Leçon: Workflow pour le deep learning orienté pour Tensorflow¶
TensorFlow et PyTorch — présentation comparative¶
Les deux frameworks dominants en deep learning partagent les mêmes fondements (tenseurs, autograd, GPU) mais diffèrent par leur philosophie et leur écosystème.
| TensorFlow / Keras | PyTorch | |
|---|---|---|
| Créateur | Meta (Facebook AI Research) | |
| Paradigme | Define-and-run (graphe statique) puis dynamique (TF 2) | Define-by-run (graphe dynamique) |
| API haut niveau | Keras (intégré) | PyTorch Lightning, fastai |
| Déploiement | TF Serving, TF Lite, TF.js, TFX | TorchServe, ONNX, TorchScript |
| Popularité | Industrie, production | Recherche académique, NLP |
TensorFlow / Keras¶
Avantages
- Déploiement complet : TF Serving (REST/gRPC), TF Lite (mobile), TF.js (navigateur), TFX (MLOps)
- API Keras intuitive : Sequential, Functional, sous-classement — progressivement complexe
- Visualisation intégrée : TensorBoard nativement supporté
- Écosystème riche : TF Hub (modèles pré-entraînés), TF Datasets, TF Probability, TF Agents
- Production éprouvée : largement adopté dans l'industrie et les systèmes embarqués
Inconvénients
- Courbe d'apprentissage plus raide pour les parties bas niveau (
tf.GradientTape, graphes) - Débogage historiquement moins intuitif (amélioré en TF 2 avec le mode eager)
- Moins dominant dans la recherche académique récente
PyTorch¶
Avantages
- Débogage naturel : graphe dynamique, erreurs lisibles avec les outils Python standards (
pdb, etc.) - Flexibilité maximale : contrôle total de la passe forward, boucles personnalisées sans friction
- Référence en recherche : majorité des papiers NLP/vision publient leur code en PyTorch
- Communauté active : HuggingFace, timm, PyTorch Lightning, fastai s'appuient sur PyTorch
- ONNX : export interopérable vers d'autres moteurs d'inférence (TensorRT, OpenVINO)
Inconvénients
- Déploiement en production plus manuel (TorchServe moins mature que TF Serving)
- Pas d'équivalent natif à TF Lite pour le mobile (nécessite ONNX ou conversion)
- Moins d'abstractions haut niveau pour les non-chercheurs
Comment choisir ?¶
| Contexte | Recommandation |
|---|---|
| Cours, initiation au DL | TensorFlow / Keras (API plus progressive) |
| Recherche, reproduction de papiers | PyTorch (dominant dans la littérature) |
| Déploiement mobile / embarqué | TensorFlow Lite |
| API web de prédiction | TF Serving ou TorchServe |
| NLP, modèles HuggingFace | PyTorch (HuggingFace natif) |
| MLOps / pipelines industriels | TFX (TensorFlow) |
Les deux frameworks convergent : TF 2 adopte le mode eager de PyTorch, PyTorch adopte des outils de déploiement similaires. La logique apprise sur l'un se transfère facilement à l'autre.
Les différentes étapes¶
- Charger les données
- Pré-traiter les données
- Construire une architecture ou importer un modèle pré-entrainé (nombre de couche, de neurones par couche, type de cellules, architecture du réseau)
- Définir les hyper-paramètre relatifs à chaque couche (fonction d'activation)
- Définir les hyper-paramètres relatifs à l'apprentissage (optimiseur, fonction de perte)
- Définir la métrique d'évaluation
- Entrainer le réseau
- Monitorer et gérer le sur-apprentissage (courbes d'apprentissange, early stopping, couche de régularisation, early stopping, batch normalisation)
- Sauvegarder le réseau
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
A partir de data set externes¶
On peut utiliser la librairie pandas pour charger des données tabulaires, par exemple:
# chargement du dataset AutoMPG de puis le site ce l'UCI
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
X = raw_dataset.drop(columns='MPG')
y = raw_dataset['MPG']
Créer des pipelines de données (module tf.data.Dataset)¶
- Une source de données qui construit un data set à partir de données en mémoire : utiliser
tf.data.DataSet.from_tensors()outf.data.Dataset.from_tensor_slices() - Une transformation de données qui construit un esemble de données à partir d'objets de
tf.data.Dataset: par exemple pour appliquer des transformations par élément avecDataSet.map()ou des transformations multi-éléments comme la création de batches avecDataset.batch
X_tensor = tf.data.Dataset.from_tensors(X)
y_tensor = tf.data.Dataset.from_tensors(y)
X_tensor
list(X_tensor.as_numpy_iterator())
Chargement d'images¶
import tensorflow as tf
IMAGE_SIZE = (224, 224)
BATCH_SIZE = 32
# Option 1 : répertoire organisé par classe
# data/train/chien/ *.jpg
# data/train/chat/ *.jpg
train_ds = tf.keras.utils.image_dataset_from_directory(
"data/train/",
image_size=IMAGE_SIZE,
batch_size=BATCH_SIZE,
label_mode='int', # 'int', 'categorical', 'binary'
shuffle=True, seed=42,
validation_split=0.2, subset='training'
)
val_ds = tf.keras.utils.image_dataset_from_directory(
"data/train/", image_size=IMAGE_SIZE, batch_size=BATCH_SIZE,
validation_split=0.2, subset='validation', seed=42
)
# Option 2 : décodage manuel (plus de contrôle)
def load_image(path, label):
img = tf.io.read_file(path)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.resize(img, IMAGE_SIZE)
img = img / 255.0 # normaliser dans [0, 1]
return img, label
dataset = (
tf.data.Dataset.from_tensor_slices((image_paths, labels))
.map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
.batch(BATCH_SIZE)
.prefetch(tf.data.AUTOTUNE)
)
Augmentation de données images¶
# Couche d'augmentation intégrée à Keras
# → appliquée uniquement pendant l'entraînement (ignorée à l'inférence)
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.1),
tf.keras.layers.RandomZoom(0.1),
tf.keras.layers.RandomBrightness(0.2),
tf.keras.layers.RandomContrast(0.2),
])
# Intégrer dans le pipeline de données
train_ds = train_ds.map(
lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=tf.data.AUTOTUNE
)
Chargement de texte¶
from tensorflow.keras.layers import TextVectorization
texts = ["texte d'exemple", "autre texte", ...]
labels = [0, 1, ...]
# Couche de vectorisation : tokenisation + encodage en entiers
vectorizer = TextVectorization(
max_tokens=10_000, # taille du vocabulaire
output_mode='int', # 'int' | 'binary' | 'count' | 'tf_idf'
output_sequence_length=128 # longueur fixe (padding / troncature)
)
vectorizer.adapt(texts) # construit le vocabulaire sur le corpus
# Pipeline tf.data
dataset = (
tf.data.Dataset.from_tensor_slices((texts, labels))
.map(lambda t, l: (vectorizer(t), l))
.batch(32)
.prefetch(tf.data.AUTOTUNE)
)
Chargement de données audio¶
Pour l'audio on travaille généralement avec des spectrogrammes (images temps-fréquence) plutôt que le signal brut, ce qui permet d'utiliser des architectures CNN.
SAMPLE_RATE = 16_000
def load_audio(path, label):
audio = tf.io.read_file(path)
audio, _ = tf.audio.decode_wav(audio, desired_channels=1)
audio = tf.squeeze(audio, axis=-1) # (n_samples,)
audio = audio[:SAMPLE_RATE] # tronquer à 1 seconde
# Transformation STFT → spectrogramme
spectrogram = tf.signal.stft(audio, frame_length=255, frame_step=128)
spectrogram = tf.abs(spectrogram) # magnitude
spectrogram = spectrogram[..., tf.newaxis] # ajouter canal (T, F, 1)
return spectrogram, label
dataset = (
tf.data.Dataset.from_tensor_slices((audio_paths, labels))
.map(load_audio, num_parallel_calls=tf.data.AUTOTUNE)
.batch(32)
.prefetch(tf.data.AUTOTUNE)
)
En utilisant les pipelines de Tensorflow¶
Dans Tensroflow, l'API de keras permet d'appliquer des pré-traitements aux données en mémoire en utilisant des couches de pré-traitements de différents types:
- pour le pré-traitement de données numériques continues (normalisation, discretisation)
- le pré-traitement de données catégorielles (enocding, ...)
- le pré-traitement de données textuelles (vectorisation)
- le pré-traitement d'images (crop, resizing, rescaling)
- l'augmentation de données d'images (crop, rotations, translations, ...)
Exemple d'implémentation d'une couche de normalisation:¶
Définition et application de la couche de normalisation:
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(X_tensor)
Exemple d'implémentation d'une couche de vectorisation de données textuelles:¶
from tensorflow.keras import layers
data = [
"ξεῖν᾽, ἦ τοι μὲν ὄνειροι ἀμήχανοι ἀκριτόμυθοι",
"γίγνοντ᾽, οὐδέ τι πάντα τελείεται ἀνθρώποισι.",
"δοιαὶ γάρ τε πύλαι ἀμενηνῶν εἰσὶν ὀνείρων:",
"αἱ μὲν γὰρ κεράεσσι τετεύχαται, αἱ δ᾽ ἐλέφαντι:",
"τῶν οἳ μέν κ᾽ ἔλθωσι διὰ πριστοῦ ἐλέφαντος,",
]
layer = layers.TextVectorization()
layer.adapt(data)
vectorized_text = layer(data)
print(vectorized_text)
Pour un exemple complet de pre-traitement, voir ce notebook
Construction du réseau de neurone¶
Architecture du modèle¶
Choix du type de réseau¶
Avec les progrès de la recherche en IA ces dernières années, de nombreux modèles ont vu le jour et de nouvelles architectures appraissent.
On peut cependant classer quelques types caractéristiques d'architecture, qu'il faudra choisir en fonction de vôtre tâche:
Le perceptron multi-couche (MLP) ou réseau dense¶
Il est généralement utilisé dans les tâches standard de classification ou de régression.
Du fait de sa propriété d'universalité, il est parfois utilisé dans certaines tâches pour approximer une fonction, par exemple la fonction d'évaluation dans les jeux à somme constante.
Les réseaux convolutifs ou Convolutionnal Neural Network (CNN)¶
Ils sont principalement utilisé dans le traitement de vision par ordinateur (images 2D et 3D), mais les CNN à 1 dimensions sont parfois également utilisés pour apprendre des motifs particuliers dans les séquences (langage, série temporelle)
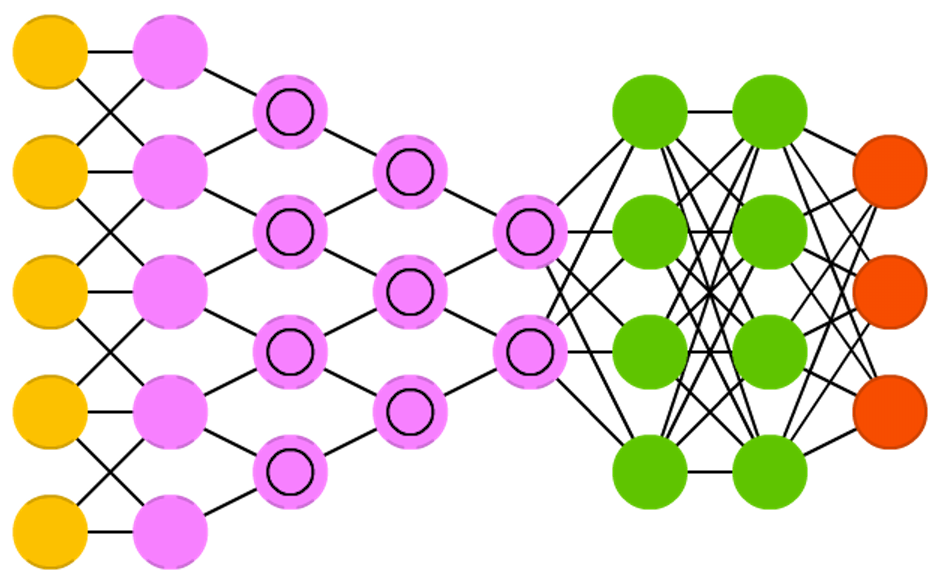
Les réseaux récurrents ou Recurrent Neural Network (RNN)¶
Ils sont principalement utilisé dans le traitement de séquences (langage, séries, temporelles, ...). Ils ont connu plusieurs variations avec les modèles intégrant des capacité de mémoire, comme les LSTM (Long Short Term Memory) et GRU (Gated Recurrent Unit)
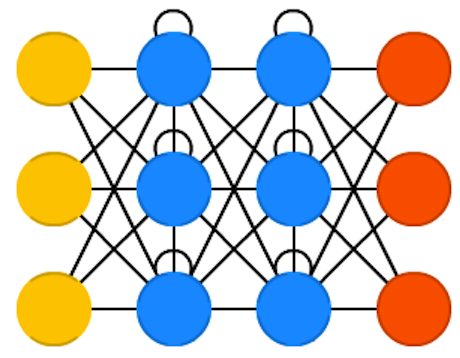
Les auto-encodeurs¶
Il s'agit d'un des rares modèles en deep learning pouvant être utilisé pour des tâches non supervisée: on utilise généralement en récupérant ses couches cachées sous forme de variables latentes, par exemple pour des tâches de segmentation de données ou pour débiaiser des données

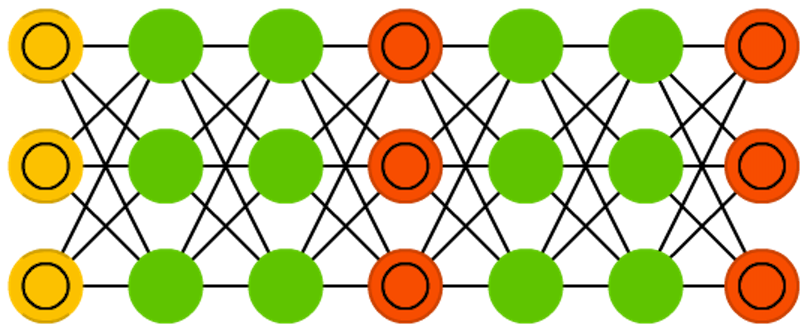
Les GAN(s)¶
Il s'agit de modèles génératifs, inventés en 2014, et qui sont devenus depuis particulièrement populaires, en particulier pour la génération d'images et de sons
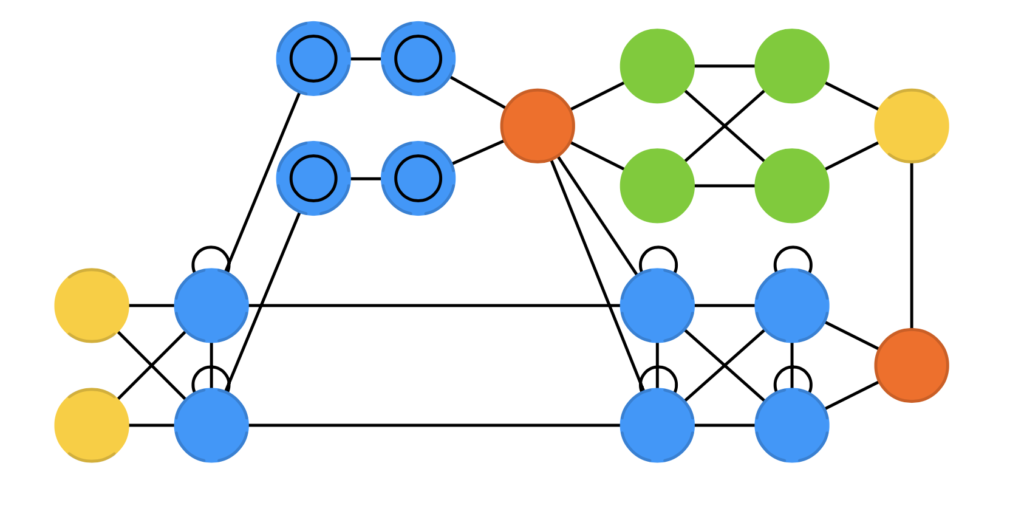
Les Transformers¶
Il s'agit d'une catégorie de très gros modèles, appartenant à la classe des réseaux attentionnels.
Ce type de réseaux utilise des mécaniques d'attention pour combattre les phénomènes de perte d'information en conservant en mémoire des états précédants du réseaux.
Inventés en 2017, ils sont principalement utilisé par apprentissage par transfert dans différentes tâches de traitement du langage, comme la génération de texte, la réponse au question, le résumé, la traduction, ...
Ils sont à la base de la plupart des Large Langage Models (LLM) dont le fameux GPT
...
Couches typiques pour l'analyse d'images (CNN)¶
| Couche | Rôle |
|---|---|
Conv2D(filters, kernel_size) |
Extraction de caractéristiques locales |
MaxPooling2D(pool_size) |
Réduction spatiale |
GlobalAveragePooling2D() |
Résumé spatial global → vecteur |
BatchNormalization() |
Normalisation des activations |
SeparableConv2D |
Conv dépthwise + pointwise (plus légère) |
model = keras.Sequential([
keras.Input(shape=(HEIGHT, WIDTH, 3)),
# Bloc convolutif
keras.layers.Conv2D(32, kernel_size=3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(pool_size=2),
keras.layers.Conv2D(64, kernel_size=3, activation='relu', padding='same'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D(pool_size=2),
keras.layers.GlobalAveragePooling2D(), # → (batch, 64)
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(n_classes, activation='softmax')
])
Couches typiques pour l'analyse de texte (NLP)¶
| Couche | Rôle |
|---|---|
Embedding(vocab_size, embed_dim) |
Token entier → vecteur dense |
LSTM(units) / GRU(units) |
Séquence avec mémoire |
Bidirectional(LSTM(...)) |
Contexte gauche + droite |
Conv1D(filters, kernel_size) |
Extraction de n-grammes locaux |
MultiHeadAttention(num_heads, key_dim) |
Mécanisme d'attention (Transformer) |
GlobalMaxPooling1D() |
Agrégation séquentielle |
model = keras.Sequential([
keras.Input(shape=(SEQ_LEN,)),
keras.layers.Embedding(VOCAB_SIZE, EMBED_DIM), # (seq_len,) → (seq_len, embed_dim)
keras.layers.Bidirectional(keras.layers.LSTM(64, return_sequences=True)),
keras.layers.Bidirectional(keras.layers.LSTM(32)), # → (batch, 64)
keras.layers.Dense(64, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(1, activation='sigmoid') # classification binaire
])
Couches typiques pour l'analyse audio¶
# Approche 1 : Conv1D sur le signal brut
model_1d = keras.Sequential([
keras.Input(shape=(SAMPLE_RATE, 1)),
keras.layers.Conv1D(64, kernel_size=80, strides=16, activation='relu'),
keras.layers.Conv1D(128, kernel_size=3, activation='relu'),
keras.layers.GlobalMaxPooling1D(),
keras.layers.Dense(n_classes, activation='softmax')
])
# Approche 2 : Conv2D sur spectrogramme (traiter l'audio comme une image)
model_2d = keras.Sequential([
keras.Input(shape=(T, F, 1)), # spectrogramme : T trames × F fréquences × 1 canal
keras.layers.Conv2D(32, 3, activation='relu'),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(64, 3, activation='relu'),
keras.layers.GlobalAveragePooling2D(),
keras.layers.Dense(n_classes, activation='softmax')
])
L'approche 2 (spectrogramme + CNN 2D) est la plus courante car elle bénéficie des architectures CNN déjà validées en vision par ordinateur.
Couches personnalisées¶
Pour des opérations non disponibles dans Keras :
class AttentionPooling(keras.layers.Layer):
"""Agrégation pondérée par attention sur une séquence."""
def __init__(self, **kwargs):
super().__init__(**kwargs)
def build(self, input_shape):
# Poids appris pour scorer chaque position
self.W = self.add_weight(
shape=(input_shape[-1], 1),
initializer='glorot_uniform',
trainable=True, name='attention_W'
)
def call(self, inputs):
# inputs : (batch, seq_len, embed_dim)
scores = tf.nn.softmax(inputs @ self.W, axis=1) # (batch, seq_len, 1)
context = tf.reduce_sum(scores * inputs, axis=1) # (batch, embed_dim)
return context
def get_config(self):
return super().get_config()
# Utilisation dans un modèle
inputs = keras.Input(shape=(SEQ_LEN, EMBED_DIM))
x = AttentionPooling()(inputs)
outputs = keras.layers.Dense(n_classes, activation='softmax')(x)
model = keras.Model(inputs, outputs)
Choix des couches : type et nombre de couches, neurones par couches¶
Il s'agit des principaux hyper-paramètres ayant un impact généralement le plus important sur les performances, il conditionne la complexité de votre réseau.
En fonction de la tâche à traiter, 3 scenarii sont possibles:
- utiliser un réseau déja pré-entrainé (apprentissage par transfert) sans le ré-entraîner: vous ne changer pas son architecture
- utiliser un réseau pré-entrainé et ré-entrainer certaines couches spécifiquement (fine tuning): vous pouvez décidez de changer certaines couches du réseau à ré-entrainer
- créer complètement l'architecture de votre réseau
Intuition¶
- nombre de neurone par couche : nombre de "motifs" différents capturé dans les données
- nombre de couches : "niveau de granularité" dans les motifs crées par votre réseau
Code avec l'API Sequential de keras¶
Cette API est pensée pour refléter une manière simple de penser le réseau comme un empilement de couches (où chaque couche à exactement un tenseur d'entrée et un tenseur de sortie):
model = tf.keras.Sequential([
# couche 1
# couche 2
# ...
])
model = tf.keras.Sequential()
model.add(...) # on passe en argument un objet layer
model.add(...)
...
Si votre réseau possède une topologie particulière (plusieurs entrée ou sorties, connexions entre couches, ...) vous devrez utiliser l'API fonctionnelle de Keras, plus souple
API Séquentielle — exemple complet¶
import tensorflow as tf
from tensorflow import keras
model = keras.Sequential([
keras.Input(shape=(n_features,)), # déclarer explicitement la forme d'entrée
keras.layers.Dense(128, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dropout(0.3),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(n_classes, activation='softmax')
])
model.summary() # résumé de l'architecture et nombre de paramètres
⚠️ L'API séquentielle ne convient pas pour les architectures avec plusieurs entrées/sorties ou des connexions résiduelles.
API Fonctionnelle — pour les architectures complexes¶
L'API fonctionnelle permet de définir le graphe de couches explicitement et supporte :
- Connexions résiduelles (skip connections — ResNet, DenseNet)
- Plusieurs entrées ou sorties
- Couches partagées
# Définir le graphe de couches
inputs = keras.Input(shape=(n_features,)) # nœud d'entrée
x = keras.layers.Dense(128, activation='relu')(inputs)
x = keras.layers.BatchNormalization()(x)
x = keras.layers.Dropout(0.3)(x)
# Skip connection : ajouter un raccourci depuis inputs
shortcut = keras.layers.Dense(64)(inputs) # projection de la dimension
x = keras.layers.Dense(64, activation='relu')(x)
x = keras.layers.Add()([x, shortcut]) # addition élément par élément
outputs = keras.layers.Dense(n_classes, activation='softmax')(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Sous-classement de keras.Model — contrôle total¶
Pour un contrôle complet sur la passe forward (boucle d'entraînement personnalisée) :
class MonReseau(keras.Model):
def __init__(self, n_classes):
super().__init__()
self.dense1 = keras.layers.Dense(128, activation='relu')
self.bn = keras.layers.BatchNormalization()
self.dropout = keras.layers.Dropout(0.3)
self.dense2 = keras.layers.Dense(64, activation='relu')
self.output_layer = keras.layers.Dense(n_classes, activation='softmax')
def call(self, inputs, training=False):
x = self.dense1(inputs)
x = self.bn(x, training=training) # BN se comporte différemment en train/inférence
x = self.dropout(x, training=training)
x = self.dense2(x)
return self.output_layer(x)
model = MonReseau(n_classes=10)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Correspondance TensorFlow / Keras ↔ PyTorch¶
| Concept | TensorFlow / Keras | PyTorch |
|---|---|---|
| Tenseur | tf.Tensor |
torch.Tensor |
| Modèle séquentiel | keras.Sequential |
torch.nn.Sequential |
| Modèle personnalisé | keras.Model (sous-classe) |
torch.nn.Module |
| Optimiseur | keras.optimizers.* |
torch.optim.* |
| Gradient automatique | tf.GradientTape |
loss.backward() |
| Mise à jour | optimizer.apply_gradients(...) |
optimizer.step() |
| Chargement données | tf.data.Dataset |
torch.utils.data.DataLoader |
| GPU | tf.device('/GPU:0') |
tensor.to('cuda') |
PyTorch — pseudo-code équivalent¶
import torch
import torch.nn as nn
class MonReseau(nn.Module):
def __init__(self, n_features, n_classes):
super().__init__()
self.fc1 = nn.Linear(n_features, 128)
self.bn = nn.BatchNorm1d(128)
self.dropout = nn.Dropout(0.3)
self.fc2 = nn.Linear(128, 64)
self.output = nn.Linear(64, n_classes)
def forward(self, x):
x = torch.relu(self.bn(self.fc1(x)))
x = self.dropout(x)
x = torch.relu(self.fc2(x))
return self.output(x) # logits (pas de softmax — intégré dans la loss)
model = MonReseau(n_features, n_classes)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
# Boucle d'entraînement
for epoch in range(n_epochs):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
loss = criterion(model(batch_X), batch_y)
loss.backward() # rétropropagation
optimizer.step() # mise à jour θ
Afficher l'architecure et les paramètres du réseau¶
model.summary()
Fonction d'activation¶
Permet d'introduire une non-linéarité dans le traitement des données, permettant au réseau d'approximer n'importe qu'elle fonction (propriété d'universalité des réseaux de neurones)
Vous pouvez choisir parmi celles disponibles dans l'API de keras ou sinon implémenter votre propre fonction d'activation.
La communauté des chercheurs et utilisateurs recommandent l'utilisation par défaut de relu car elle est rapide à calculer
Exemple avec un réseau dense (MLP):¶
model = tf.keras.Sequential([
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(10)
])
Optimiseur & learning rate¶
Il s'agit de l'algorithme utilisé pour trouver les meilleurs paramètres, ceux qui minimisent l'erreur mesurée par la fonction de perte
En deep learning on utilise quasi exclusivement des variantes de l'algorithme de descente de gradient stochastique calculée par mini-batches que vous pouvez choisir parmi ceux disponibles dans l'API de keras
La communauté des chercheurs et utilisateurs recommande l'utilisation par défaut de Adam car il combine plusieurs propriétés avantageuses:
- intégre un
learning rateadaptatif : il varie en fonction de l'historique passé des gradients - intégre les
moments: ajoute de l'inertie au calcul du gradient (en gardant en mémoire les valeurs précédantes du gradient), ce qui peut aider le gradient à ressortir d'un minimum local - intégre la capacité à sélectionner les features ayant été le moins mise à jour à l'itération précédante (comme
AdaGrad) - il est rapide à calculer (par rapport à
AdaGrad) - il fonctionne bien avec des réseaux de grande taille
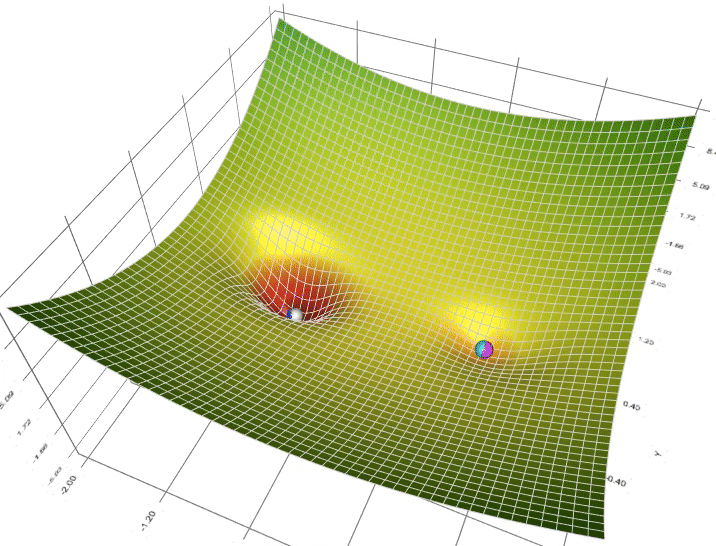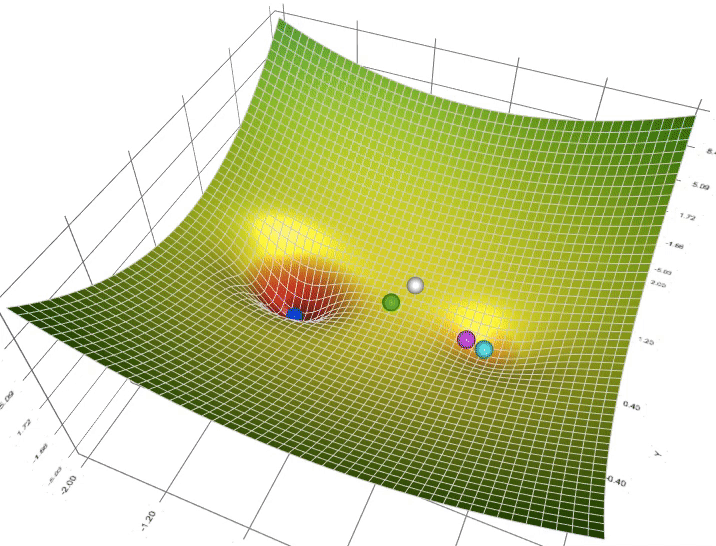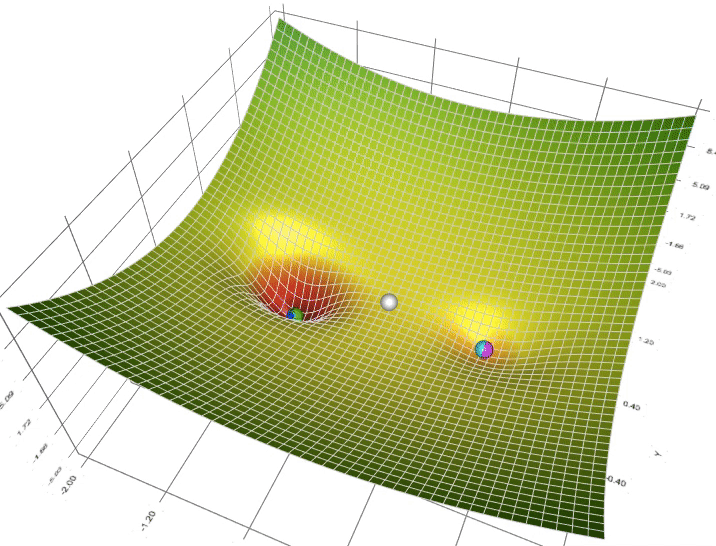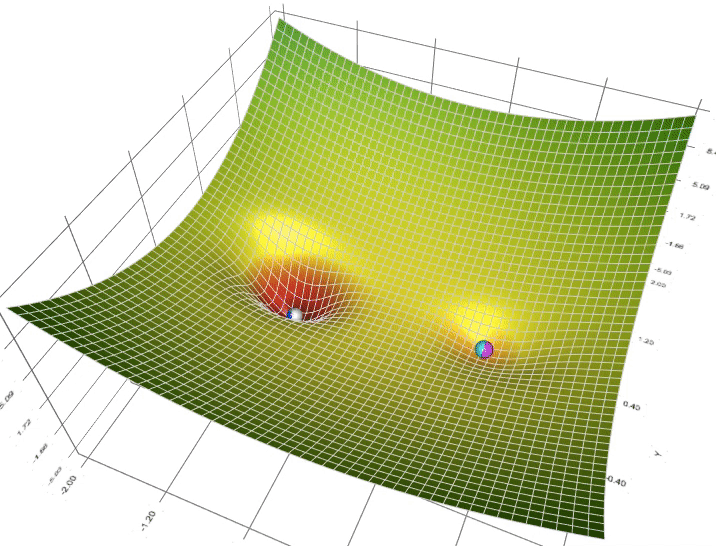
Pour les réseaux récurrents, on utilise plus souvent historiquementRMSprop
Pour les embeding, Adamax donne généralement de meilleurs résultats que Adam
Exemple avec l'optimiseur Adam :¶
model.compile(optimizer = tf.keras.optimizers.adam())
Fonction de perte (loss) : $L(\theta_1,\theta_2, \cdots \theta_i)$¶
La fonction de perte mesure l'erreur faite par l'optimiseur au moment de l'apprentissage.
Mathématiquement, elle doit être une fonction continue et différenciable pour chaque $\theta_i$. En pratique, on peut se la représenter comme un vallée dont la topgraphie est "lisse" mais complexe
En fonction de la tâche à résoudre (classification, régréssion, ...), vous pouvez choisir parmi celles disponibles dans l'API de keras ou sinon implémenter la votre.
Par exemple, pour la classification on utilise souvent la binary cross entropy ou log loss, car elle renvoie des valeurs qui varient de manière plus "lisse":
$$ Log Loss = -\frac{1}{n}\sum_{i=0}^{n}y_ilog(\hat y_i) + (1 - y_i)log(1 - \hat y_i) $$
Utilisation dans keras :¶
# si vous choisissez parmi la liste proposées
model.compile(loss = "binary_crossentropy")
# ou en utlisant l'objet dédié (plus flexible)
loss = keras.losses.BinaryCrossentropy(...)
model.compile(loss = loss)
# si vous choisissez de coder votre propre loss
def custom_mse(y_true, y_pred):
squared_diff = tf.square(y_true - y_pred)
return tf.reduce_mean(squared_diff)
model.compile(loss=custom_mse)
Métrique d'évaluation¶
Elle mesure la performance de votre modèle à résoudre la tâche, c'est à dire une fois l'apprentissage effectué (en général, elle est différente de la fonction de perte). Il est donc important de bien la choisir en fonction des caractéristiques de la tâche !
Vous pouvez choisir parmi celles disponibles dans l'API de keras ou sinon implémenter la votre.
Exemple avec la métrique RMSE¶
On définit la métrique a utiliser avant l'apprentissage:
model.compile(metrics=[tf.keras.metrics.RootMeanSquaredError()])
On évalue la performance du modèle entrainé sur le jeu de test:
loss, accuracy = model.evaluate(X_test,y_test)
Batch size (mini-batch gradient descent)¶
Dans la descente de gradient stochastique et ses dérivées, le gradient se calcule de manière privilégiée en utilisant un petit paquet de b données, les batches:
- entraînement plus rapide car parallélisable
- permet d'utiliser des learning rate plus important
- facilite la convergence de la descente de gradient
Il faut trouver un compromis entre des batches de petite taille (rapide à calculer mais mauvaise estimation du gradient) et gros batches (lent à calculer mais bonne estimation du gradient):
la recherche recommande généralement une valeur maximale de 32,
en pratique on utilise souvent batch_size=16 ou batch_size=32
ou des tailles plus grandes lorsque l'on a un petit dataset
Nombre d'epochs¶
Il s'agit du nombre d'itérations au cours desquelles le réseau a fait une passe d'optimisation des paramètres avec toutes les données du data set Une epoch est divisée en autant d'itérations de mise à jour des paramètres qu'il y a de batches :
$(\theta_0^0, \theta_1^0, ...,\theta_n^0) \rightarrow (\theta_0^1, \theta_1^1, ..., \theta_n^1)$ sur le batch $b_0=(X_1, X_2, ..., X_{10})$
$\theta_0^1, \theta_1^1, ...,\theta_n^1) \rightarrow (\theta_0^2, \theta_1^2, ..., \theta_n^2)$ sur le batch $b_1=(X_{10}, X_{11}, ..., X_{20})$
...
Il faut trouver un compromis entre laisser le réseau s'entrainer sur peu d'epochs, avec le risque qu'il sous apprenne, et beaucoup d'epoches, avec le risque qu'il sur apprenne
Conseil¶
Dans une première itération, il vaut mieux spécifier un nombre d'epochs important pour vérifier si votre réseau est capable de sur-apprendre, vous pourrez diminuer ensuite ce nombre d'epochs pour atteindre un meilleurs compromis
Prévention du sur-apprentissage (overfitting)¶
- jeu d'apprentissage : sert pour l'entrainement du modèle
- jeu de validation : sert à valider les performances de votre modèle (pour estimer l'overfitting, comparer des modèles, ...)
- jeu de test : sert a évaluer la capacité de votre modèle à généraliser en simulant de nouvelles données
Comme en machine learning classique, c'est une approche plus complète pour segmenter le jeu d'apprentissage, mais elle peut être particulièrement longue à calculer en deep learning !
Entraînement¶
Ressources de calcul¶
Avant de lancer votre entrainement, il est conseillé d'avoir configuré vos ressources de calcul (locales ou cloud) pour utiliser des ressouces permettant de paralléliser l'entraînement, au contraire du CPU faiblement parallélisable. Pour raccourcir le temps de calcul, il est conseillé d'utiliser :
- les GPU (Graphical Processing Unit) : les processeurs de la carte graphique, faiblement cadencés, mais nombreux et parallélisables
- les TPU (Tensor Processing Unit): processeurs développés par Google pour faire uniquement du calcul de tenseur, utilisables pour le deep learning
Code dans tensorflow :¶
Après avoir défini l'architecture du réseau, on spécifie ses hyper-paramètres d'apprentissage:
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.adam(learning_rate=base_learning_rate/10),
metrics=[tf.keras.metrics.RootMeanSquaredError()])
Puis on entraine le réseau avec la méthode .fit , en spécifiant un pourcentage de données pour la validation :
history = model.fit(X_train, y_train,
validation_split=0.3,
batch_size=16,
epochs=100)
ou explicitement des données de validation (utile par exemple pour faire une cross-validation) :
history = model.fit(X_train, y_train,
validation_data=(X_val, y_val),
batch_size=16,
epochs=100)
Réglages des hyper paramètres¶
Définition¶
De même que dans le Machine Learning classique, les hyperparamètres sont des variables qui régissent le processus de formation d'un modèle : ils sont constants tout au long du processus d'apprentissage et ne sont pas appris.
On en distingue deux types :
- ceux liés au modèles : ils influencent l'architecture du modèle que vous allez sélectionner
par ex: le nombre de couches, le nombre de neurones par couche, ... - ceux liés à l'algorithmie : ils influencent la vitesse et la qualité de l'algorithme d'apprentissage
par ex: le taux d'apprentissage de la descente de gradient stochastique, le nombre de batch, ...
Différents variantes d'algorithmes¶
Dans tensorflow vous allez utiliser le module Keras Tuner pour assurer le réglage des hyper paramètres suivant des méthodes différentes :
RandomSearch: tire au hasard les paramètres à tester (suivant une loi de probabilité)Hyperband: sélectionne les paramètres en les mettant en compétition à la manière d'un tournoiBayesianOptimization: utilise les statistiques bayesienne pour l'optimisationSklearn: utilise une recherche exhaustive (GridSearch)
Conseil : Hyperband peut être un bon choix pour réduire le temps de calcul de la recherche
Application dans tensorflow¶
Vous définisez un hypermodèle ainsi qu'un espace de recherche :
- soit en créant une fonction dédiée
- soit en créant une sous classe de
Keras Tuner
Exemple d'une chaine de traitement avec la méthode hyperband¶
On définit une fonction pour créer notre hypermodèle et son espace de recherche :
def model_builder(hp):
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
# Tune the number of units in the first Dense layer
# Choose an optimal value between 32-512
hp_units = hp.Int('units', min_value=32, max_value=512, step=32)
model.add(keras.layers.Dense(units=hp_units, activation='relu'))
model.add(keras.layers.Dense(10))
# Tune the learning rate for the optimizer
# Choose an optimal value from 0.01, 0.001, or 0.0001
hp_learning_rate = hp.Choice('learning_rate', values=[1e-2, 1e-3, 1e-4])
return model
Puis on instancie le tuner, en choisissant une stratégie (ici la méthode hyperband):
tuner = kt.Hyperband(model_builder,
objective='val_accuracy',
max_epochs=10,
factor=3, #paramètre spécifique à la méthode hyperband
directory='my_dir',
project_name='intro_to_kt')
Enfin on lance le calcul de la recherche des hyperparamètres :
tuner.search(img_train, label_train, epochs=50, validation_split=0.2, callbacks=[stop_early])
Une fois le calcul terminé, on accède aux hyperparamètres sélectionnés:
# Get the optimal hyperparameters
best_hps=tuner.get_best_hyperparameters(num_trials=1)[0]
best_hps.get('units') #pour le nombre de neurone
best_hps.get('learning_rate') #pour le learning rate
...
On peut ensuite entrainer le modèle ainsi sélectionné :
# entrainement du modèle sélectionné avec les meilleurs hp
model = tuner.hypermodel.build(best_hps)
history = model.fit(img_train, label_train, epochs=50, validation_split=0.2)
# résultats des epochs calculées
val_acc_per_epoch = history.history['val_accuracy']
best_epoch = val_acc_per_epoch.index(max(val_acc_per_epoch)) + 1
Pour aller plus loin¶
Pour un tutoriel complet voir le tutoriel de tensorflow et pour plus de details la page de documentation dédiées de keras
En particulier, pour les applications liées à la vision par ordinateur, keras propose des hypermodèles spécialisés, comme HyperResNet ou HyperXception utilisable pour les modèles pré-entrainés correspondant
Dans certaines tâches, comme celles de vision par ordinateur, il est courant d'utiliser des réseaux de neurones pré-entrainés, souvent sur de très gros dataset et avec des architectures à l'état de l'art.
On peut alors bénéficier de l'apprentissage de ces réseaux pré-entrainés pour les adapater à notre tâche:
- sans les ré-entrainer : pour bénéficier de leur capacité d'extraction automatisée de features
- en ne ré-entraînant que quelques couches spécifiques : on peut ré-entraine certaines couches (souvent les plus externes) sur un dataset spécifique à notre tâche, en conservant l'apprentissage effectué dans les autres couches (les valeurs des paramètres y sont figées)
Implémentation dans tensorflow¶
On peut facilement charger un modèle pré-entrainé depuis tensorflow, par exemple MobileNetV2 pour l'extraction de features:
from tf.keras.applications import MobileNetV2
base_model = MobileNetV2(include_top=False, # on ne charge pas les couche finales
weights='imagenet')
ou pour le fine-tuning :
# couche à partir de laquelle on ré-entraine les couches
fine_tune_at = 100
# on gèle les couches avant
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Ensuite on spécifie les hyper-paramètres d'apprentissage :
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.adam(),
metrics=['accuracy'])
Et on ré-entraine une partie des couches du modèle pré-entrainé, à partir de la dernière epoch:
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
Gestion du compromis biais/variance¶
Détection de l'overfitting: les courbes d'apprentissage¶
On peut définir une fonction pour tracer les courbes d'apprentissage en fonction du nombre d'epochs :
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, 10])
plt.xlabel('Epoch')
plt.ylabel('Error')
plt.legend()
plt.grid(True)
Exemple de courbes d'apprentissage:
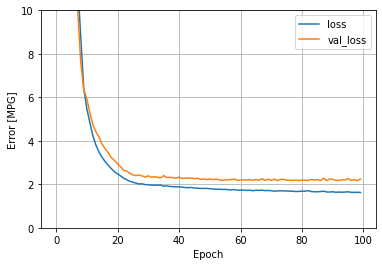
Encore mieux : utiliser Tensorboard pour le monitoring¶
Tensorboard est un tableau de bord interactif qui vous permet de mesurer plusieurs métriques pour le monitoring au travers de vos itérations :
Il se définit comme un callback :
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir= ...)
et est appelé au moment du fit
history = model.fit(X_train, y_train,
validation_split=0.3,
batch_size=16,
epochs=100,
callbaks = [tensorboard_callback])

Réduction de l'overfitting¶
Plutôt que de spécifier un nombre d'epoch fixe, il est possible de fixer un critère automatique d'arrêt qui sera vérifié à la fin de chaque epoch (par un callback)
Suivant ce critère, l'apprentissage sera stoppé a une epoch donnée si elle a empirée par rapport aux k epochs précédentes
from tensorflow.keras.callbacks import EarlyStopping
es = EarlyStopping()
history = model.fit(X_train, y_train,
validation_split=0.3,
batch_size=16,
epochs=1000, # on peut spécifier un grand nombre d'epoch pour être sur qu'elle ne soient pas une limite
callbacks = [es])
On peut fixer une patience, spécifiant le nombre d'epoch a attendre si il n'y a pas d'amélioration de l'entraînement :
es = EarlyStopping(patience=20)
Il est aussi courant de conserver les valeurs des paramètres à partir de l'epoch ayant enregistré les meilleurs valeurs des paramètres (avant le délai de patience)
es = EarlyStopping(patience=20, restore_best_weights=True)
model.fit(X_train, y_train,
batch_size=16,
epochs=1000,
validation_split=0.3,
callbacks=[es])
Comme dans le machine learning classique, on peut introduire des procédures de régularisation pour contraindre l'apprentissage des paramètres à trouver des valeurs moins grandes
Les méthodes les plus classiques de régularisation utilisent les normes L1 et L2:
$$ L2~Loss = Loss + \alpha \sum_{i}\theta_i^2$$
$$ L1~Loss = Loss + \alpha \sum_{i}|\theta_i|$$
Dans Tensorflow, la régularisation est pensée pour être employée couche par couche, et s'appliquer sur :
- les poids des neurones :
kernel_regularizer - les biais des neurones :
biais_regularizer - la sortie de la fonction d'activation :
activity_regularizer
Exemple d'implémentation :¶
# from tensorflow.keras import regularizers, Sequential, layers
reg_l1 = regularizers.L1(0.03)
reg_l2 = regularizers.L2(0.01)
reg_l1_l2 = regularizers.l1_l2(l1=0.001, l2=0.001)
model = Sequential()
# régularisation sur le poids des neurones
model.add(layers.Dense(100, activation='relu', kernel_regularizer=reg_l1))
# régularisation sur le biais des neurones
model.add(layers.Dense(100, activation='relu', bias_regularizer=reg_l2))
# régularsisation sur la sortie de la fonction d'activation
model.add(layers.Dense(100, activation='relu', activity_regularizer=reg_l1_l2))
Il s'agit d'un type de régularisation spécifique au deep learning, dans lequel on vient "éteindre" aléatoirement la sortie de neurones dans le réseau, au moment de l'apprentissage. Pratiquement cela à pour effet de :
- empêcher les neurones d'adapter leur paramètres en fonction d'observations d'entrée spécifiques
- forcer le réseau à utiliser moins de paramètres pendant son apprentissage (principe de parcimonie)
Implémentation¶
Ici encore, l'implémentation de tensorflow se fait sous forme de couches virtuelles et on peut appliquer le dropout à n'importe qu'elle couche:
# dropout avec 20% de neurones éteint dans cette couche
model.add(layers.Dense(100, activation='relu'))
model.add(layers.Dropout(rate=0.2))
Elle consiste à normaliser la sortie d'une couche, calculée avec les données de chaque batch et joue un rôle similaire à la régularisation
model.add(BatchNormalization())
Elle joue un rôle similaire à la régularisation
Afin de faire facilement plusieurs itérations de votre chaîne de traitement, il est recommandé de sauvegarder, pour chaque itération vos modèles entrainés :
Le plus simple : Via keras.model¶
Pour sauvegrader un modèle entrainé :
model.save(filepath)
Pour le charger :
tf.keras.models.load_model()
De manière plus complète :¶
Le format SavedModel qui enregistre le modèle de manière indépendante au code source qui la crée (cela peut être utile pour gérer son déploiement)
Déployer un modèle TensorFlow¶
Une fois sauvegardé au format SavedModel ou .keras, un modèle peut être déployé selon plusieurs cibles.
TensorFlow Serving — API REST en production¶
TF Serving expose votre SavedModel via une API REST ou gRPC sans modifier le code Python.
# Lancer le serveur (Docker)
docker run -p 8501:8501 \
--mount type=bind,source=$(pwd)/mon_modele/,target=/models/mon_modele \
-e MODEL_NAME=mon_modele \
tensorflow/serving
# Appeler l'API depuis Python
import requests, json
data = json.dumps({"instances": X_test[:5].tolist()})
response = requests.post(
"http://localhost:8501/v1/models/mon_modele:predict",
data=data, headers={"Content-Type": "application/json"}
)
predictions = response.json()['predictions']
TensorFlow Lite — mobile et embarqué¶
TF Lite convertit un modèle en un format compact (.tflite) pour Android / iOS / Raspberry Pi / microcontrôleurs.
import tensorflow as tf
# Convertir
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# Optionnel : quantification (réduit taille et temps d'inférence)
converter.optimizations = [tf.lite.Optimize.DEFAULT] # quantification dynamique
tflite_model = converter.convert()
with open('modele.tflite', 'wb') as f:
f.write(tflite_model)
# Inférence avec l'interpréteur TFLite
interpreter = tf.lite.Interpreter(model_path='modele.tflite')
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
interpreter.set_tensor(input_details[0]['index'], X_test[:1].astype('float32'))
interpreter.invoke()
output = interpreter.get_tensor(output_details[0]['index'])
TensorFlow.js — dans le navigateur¶
# Conversion depuis Python
import tensorflowjs as tfjs # pip install tensorflowjs
tfjs.converters.save_keras_model(model, 'tfjs_model/')
// Chargement et prédiction en JavaScript
const model = await tf.loadLayersModel('tfjs_model/model.json');
const inputTensor = tf.tensor2d([[...]], [1, n_features]);
const prediction = model.predict(inputTensor);
prediction.print();
TFX — pipelines de production (MLOps)¶
TensorFlow Extended (TFX) automatise l'ensemble du cycle de vie ML en production : ingestion → validation → transformation → entraînement → évaluation → déploiement.
# Exemple de pipeline TFX simplifié (pseudo-code)
import tfx
pipeline = tfx.dsl.Pipeline(
pipeline_name='mon_pipeline',
components=[
tfx.components.CsvExampleGen(input_base=data_dir),
tfx.components.StatisticsGen(examples=...),
tfx.components.SchemaGen(statistics=...),
tfx.components.Transform(examples=..., schema=..., module_file='transform.py'),
tfx.components.Trainer(module_file='trainer.py', transformed_examples=...),
tfx.components.Evaluator(examples=..., model=...),
tfx.components.Pusher(model=..., push_destination=serving_dir)
]
)
Tableau récapitulatif — options de déploiement¶
| Solution | Cible | Format | Cas d'usage |
|---|---|---|---|
model.save() + rechargement |
Python | .keras / SavedModel |
Scripts et notebooks |
| TF Serving | Serveur REST/gRPC | SavedModel | API de prédiction en production |
| TF Lite | Mobile / embarqué | .tflite |
Android, iOS, Raspberry Pi |
| TF.js | Navigateur | JSON + binaire | Applications web sans serveur |
| TFX | Pipeline MLOps | — | Déploiement industriel continu |
| ONNX | Interopérabilité | .onnx |
Export cross-framework (PyTorch → …) |
Récapitulatif d'un réseau basique (pseudo code)¶
Charger et prétraiter les données¶
# chargez et prétraitez vos données
# transforme le data set X_train, y_train en tenseur
X_train = tf.data.Dataset.from_tensors(X_train)
y_train = tf.data.Dataset.from_tensors(y_train)
# applique des couches de pre-traitement
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(tensor_dataset)
X_train = normalized(X_train)
y_train = normalized(y_train)
Définir le réseau¶
# construit le modèle (ici avec des couches denses)
model = Sequential()
model.add(layers.Dense(100, activation=..., kernel_regularizer=...))
model.add(layers.Dense(100, activation=..., bias_regularizer=...))
model.add(layers.Dense(100, activation=..., bias_regularizer=...))
...
# [Optionnel] applique des couches spécifiques (Normalisation, Drop out, Batch Normalisation)
model.add(layers.Dropout(rate=0.2))
model.add(BatchNormalization())
# régularisation sur le poids des neurones
reg_l1 = regularizers.L1(0.03)
model.add(layers.Dense(100, activation='relu', kernel_regularizer=reg_l1))
# régularisation sur le biais des neurones
reg_l2 = regularizers.L2(0.01)
model.add(layers.Dense(100, activation='relu', bias_regularizer=reg_l2))
# régularsisation sur la sortie de la fonction d'activation
reg_l1_l2 = regularizers.l1_l2(l1=0.001, l2=0.001)
model.add(layers.Dense(100, activation='relu', activity_regularizer=reg_l1_l2))
# afficher les paramètres du modèle
model.summary()
# spécifie loss, optimizer et métrique d'évaluation
model.compile(loss=...,
optimizer= ...,
metrics=[...])
Entrainer, évaluer et sauvegarder le réseau¶
# définition des callbacks early stopping & Tensorboard
es = EarlyStopping(min_delta=...,patience=...)
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir= ...)
history = model.fit(X_train,y_train,
validation_split=...,
batch_size=16,
epochs=...,
callbacks = [es, tensorboard_callback, ...])
# affiche tensorboard (dans un notebook)
%tensorboard --logdir votre_path/fit
# évaluer les performances du modèle
loss, accuracy = model.evaluate(X_test,y_test)
# sauvegarder le modele
model.save(filepath, ...)
Sources¶
- La jungle des différents types de réseaux de neurones profonds, par The Asimov Institute
- Les sections tutorials et guide de tensorflow