Leçon: Chaîne de traitement (workflow) en machine learning¶
Les différentes étapes¶
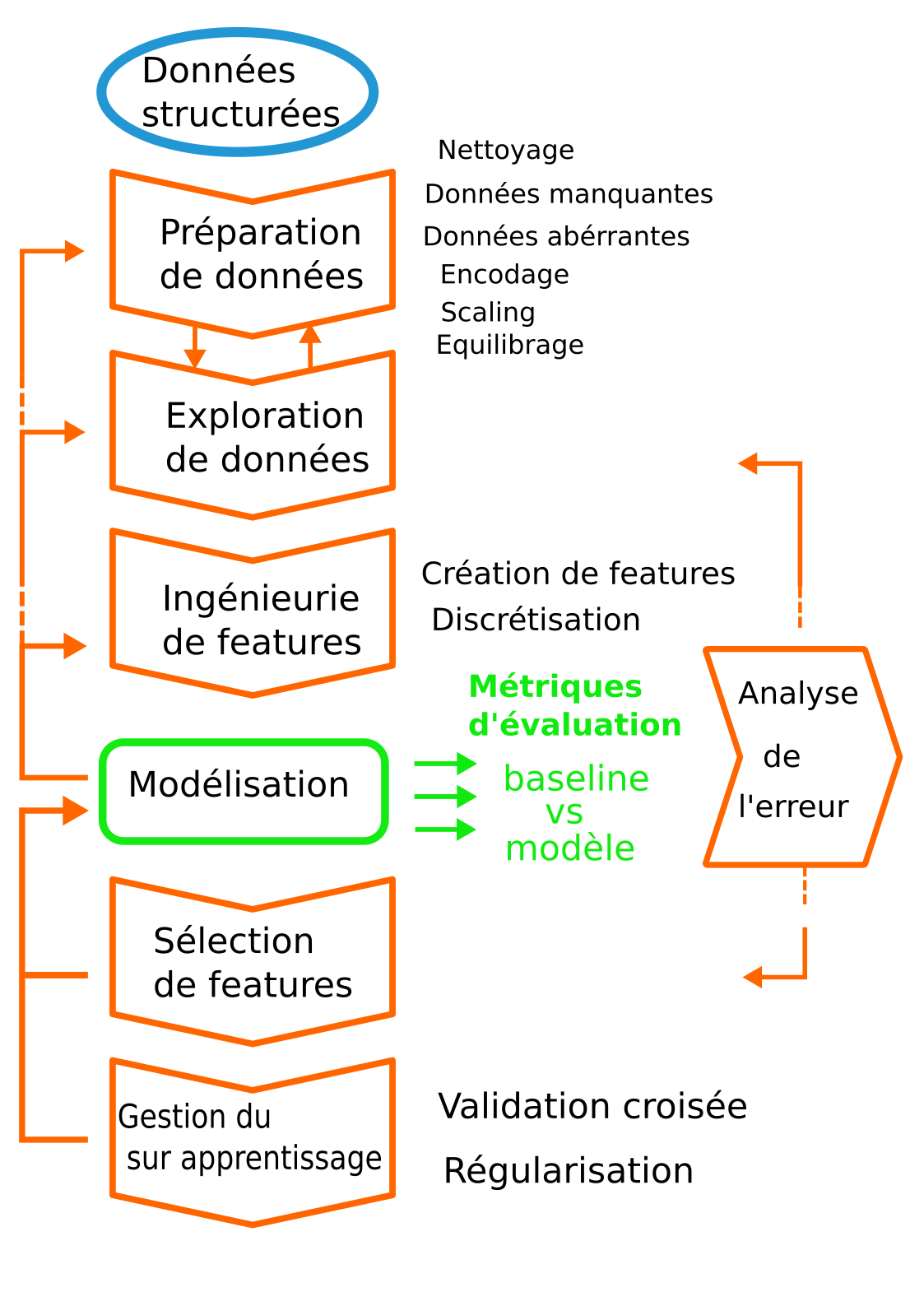
Bonnes pratiques (minimales) pour la construction de votre chaine de traitement¶
Organiser votre code de manière modulaire pour faciliter le lancement d'un grand nombre d'itérations
Sauvegarder les résultats de vos traitements : data set pré-traité (par ex avec pandas), modèle entrainé : préférez joblib pour vos modèles entrainés (ou utiliser la librairie généraliste pickle de pyhton)
joblib.save(model, path)
joblib.dump(model, path)
Enregistrer l'évolution des performances au fil des itérations: Par exemple avec mlflow
Etapes de traitement quasi-indispensables (pseudo-code)¶
Utiliser la méthode hold-out¶
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=..., random_state=...)
# fixer le random state à une valeur entière pour la reproductibilié
Pour apprendre et appliquer une transformation (souvent pendant le pré-traitement)¶
transformer = NomTransformation(parametres)
transformer.fit(X_train)
transformer.transform(X_train)
⚠️ Attention au risque de data leakage ☢️: Ne pas appliquer de transformation apprise en dehors du jeu d'apprentissage !
On apprend les transformation uniquement sur le jeu d'apprentissage, et on applique ces transformations à la fois sur celui d'apprentissage et de test
Exemple : appliquer un RobustScaler aux données¶
from sklearn.preprocessing import RobustScaler
X_train = [[ 1., -2., 2.],
[ -2., 1., 3.],
[ 4., 1., -2.]]
transformer = RobustScaler().fit(X_train)
transformer.transform(X_train)
array([[ 0. , -2. , 0. ],
[-1. , 0. , 0.4],
[ 1. , 0. , -1.6]])
Pour entrainer un modèle¶
model = NomDuModele(parametres,hypermarametres)
model.fit(X_train,y_train) # apprentissage supervisé
model.fit(X_train) # apprentissage non supervisé
Attention à toujours faire une optimisation ! ⚠️⚠️¶
Une erreur classique est d'entraîner, par facilité, un modèle avec les paramètres par défaut.
❌❌❌❌❌
model = NomDuModele()
model.fit()
❌❌❌❌❌
Ca n'est pas une bonne approche, car les paramètres utilisés par défaut ne donnent généralement pas des performances et/u une intreprétabilité optimale, et peuvent même tendre au sur apprentissage (en particulier les méthodes basées sur les arbres de décision)
Vous devez TOUJOURS optimiser votre modèle pour trouver les paramètres les optimaux possible à utiliser lors de l'entrainement:
- ✅ soit en utilisant un optimiseur spécifique à votre modèle : par exemple, les
moindres carrés(pour la régression) , ladescente de gradient(réseaux de neurones et méthodes de boosting) - ✅ soit en utilisant des méthodes d'optimisation généralistes ! par exemple en utilsant des packages dédiés comme Optuna
- ✅ sinon, a minima avec des méthodes brute force comme le
GridSearchCV
Les modèles qui possèdent un optimiseur spécifique déja implémenté¶
Certains modèles possèdent des algorithmes d'optimisation spécifiques qui permettent de trouver les paramètres optimaux de manière plus efficace qu'avec un GridSearchCV.
Rappel : la méthode des moindres carrés (résolution analytique)¶
Nous avons vu qu'elle revient à minimiser la somme des écarts au carré entre les prédictions et les erreurs, comme le montre cet exemple interactif
Par exemple, dans la régression linéaire, dont l'équation est :
$\hat y = X\theta + \epsilon$
avec :
- $X$ représente la matrice de vos données contenant p variables et n observations
- $\theta$ le vecteur des paramètres à apprendre
- $\hat y$ les valeurs de $y$ prédites par notre modèle
On utilise la loss fonction : $$loss(\theta) = ||\hat y_i−y_i||_2= \sqrt{(\hat y_1 - y_1)^2 + \ldots +(\hat y_n - y_n)^2}$$
L'optimisation revient à minimiser la loss fonction : $argmin_\theta~loss$
Dont la solution anlytique (exacte) est : $$\hat \theta = (X^TX)^{-1}X^Ty$$
1.Régression linéaire avec optimisation analytique (moindres carrés)¶
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet
# Résolution analytique (pseudo-inverse)
model = LinearRegression()
model.fit(X_train, y_train)
# Ridge avec solver spécifique
model = Ridge(
alpha=1.0,
solver='auto' # 'auto', 'svd', 'cholesky', 'lsqr', 'sparse_cg', 'sag', 'saga', 'lbfgs'
)
# Lasso avec descente de coordonnées
model = Lasso(
alpha=1.0,
max_iter=1000,
tol=1e-4,
selection='cyclic' # 'cyclic' ou 'random'
)
# ElasticNet
model = ElasticNet(
alpha=1.0,
l1_ratio=0.5, # ratio L1/L2
max_iter=1000
)
2. Régression avec optimisation automatique de la régularisation¶
LassoCV / RidgeCV / ElasticNetCV
from sklearn.linear_model import LassoCV, RidgeCV, ElasticNetCV
# Optimisation automatique du paramètre alpha par cross-validation
model = LassoCV(
alphas=[0.001, 0.01, 0.1, 1, 10], # None = auto
cv=5,
max_iter=1000
)
model.fit(X_train, y_train)
print(f"Meilleur alpha: {model.alpha_}")
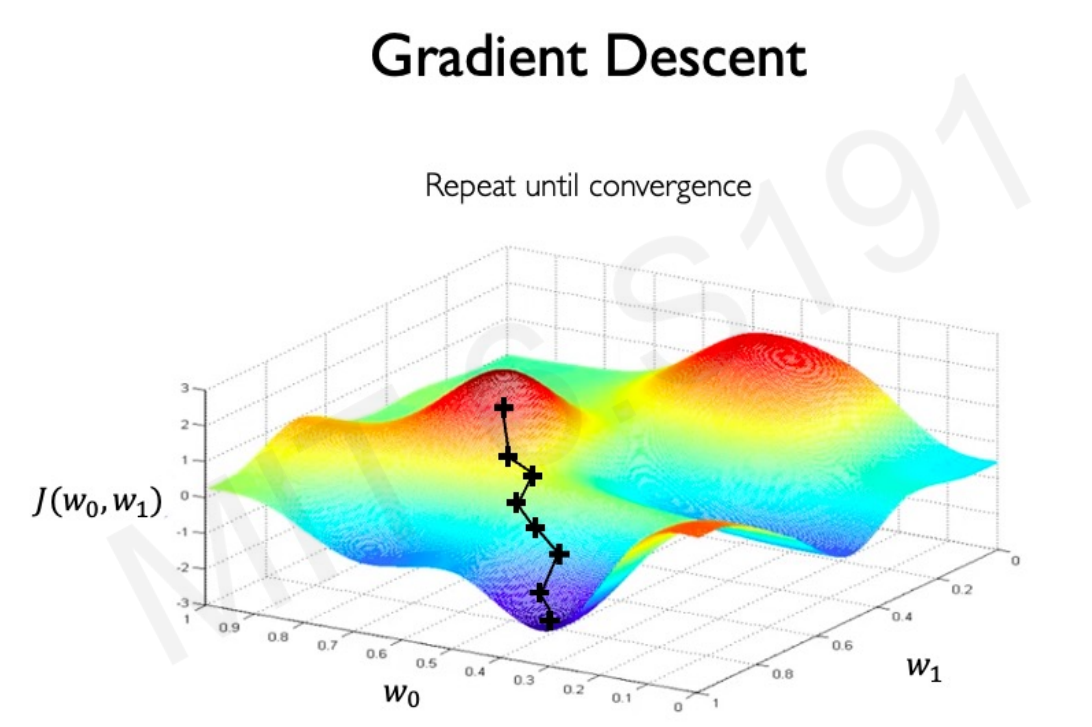
Intuition : la descente de gradient¶
On peut imaginer l'espace des paramètres à minimser comme une vallée, dont on va chercher le minimum en cherchant pas à pas le chemin de plus grande pente
Algorithme :
1.Intialise au hasard des valeurs de paramètre \theta
2.Répète jusqu'à convergence:
3.Calcule le gradient de la loss function $\nabla J(\beta)$
4.Mets à jour les paramètres $\mathbf{\beta} \leftarrow \mathbf{\beta} - \eta \nabla_{\mathbf{\beta}} J(\mathbf{\beta})$ avec $\eta$ le learning rate.
5.renvoie les paramètres optimisés
1. Modèles linéaires avec descente de gradient stochastique¶
from sklearn.linear_model import SGDClassifier, SGDRegressor
model = SGDClassifier(
loss='log_loss', # fonction de perte ('hinge', 'log_loss', 'squared_error'...)
penalty='l2', # régularisation ('l1', 'l2', 'elasticnet')
alpha=0.0001, # coefficient de régularisation
learning_rate='optimal', # stratégie ('constant', 'optimal', 'invscaling', 'adaptive')
eta0=0.01, # learning rate initial
max_iter=1000,
early_stopping=True, # arrêt anticipé sur validation
)
model.fit(X_train, y_train)
LogisticRegression avec solver optimisé
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(
solver='lbfgs', # optimiseurs: 'lbfgs', 'newton-cg', 'newton-cholesky', 'sag', 'saga'
max_iter=100,
tol=1e-4 # tolérance pour la convergence
)
model.fit(X_train, y_train)
| Solver | Description | Recommandé pour |
|---|---|---|
lbfgs |
Quasi-Newton (défaut) | Petits datasets |
sag |
Stochastic Average Gradient | Grands datasets |
saga |
Variante de SAG avec L1 | Grands datasets, sparse |
newton-cg |
Newton Conjugate Gradient | Multiclass |
2. Réseaux de neurones¶
from sklearn.neural_network import MLPClassifier, MLPRegressor
model = MLPClassifier(
hidden_layer_sizes=(100, 50),
solver='adam', # optimiseurs: 'adam', 'sgd', 'lbfgs'
learning_rate='adaptive', # 'constant', 'invscaling', 'adaptive'
learning_rate_init=0.001,
alpha=0.0001, # régularisation L2
max_iter=200,
early_stopping=True,
validation_fraction=0.1,
n_iter_no_change=10,
beta_1=0.9, # paramètres Adam
beta_2=0.999
)
model.fit(X_train, y_train)
| Solver | Description | Recommandé pour |
|---|---|---|
adam |
Adaptive Moment Estimation (défaut) | Usage général |
sgd |
Descente de gradient stochastique | Contrôle fin du learning rate |
lbfgs |
Quasi-Newton | Petits datasets |
3. Méthodes de Boosting avec learning rate¶
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(
n_estimators=100,
learning_rate=0.1, # taux d'apprentissage (shrinkage)
max_depth=3,
subsample=0.8, # fraction d'échantillons par arbre
validation_fraction=0.1,
n_iter_no_change=10, # early stopping
tol=1e-4
)
model.fit(X_train, y_train)
HistGradientBoostingClassifier / HistGradientBoostingRegressor (plus rapide pour grands datasets)
from sklearn.ensemble import HistGradientBoostingClassifier
model = HistGradientBoostingClassifier(
learning_rate=0.1,
max_iter=100, # nombre de boosting iterations
max_depth=None,
early_stopping='auto', # True, False, 'auto'
validation_fraction=0.1,
n_iter_no_change=10,
tol=1e-7,
l2_regularization=0.0
)
model.fit(X_train, y_train)
from sklearn.svm import SVC, SVR
model = SVC(
kernel='rbf',
C=1.0,
gamma='scale',
max_iter=-1, # -1 = pas de limite
tol=1e-3,
shrinking=True # heuristique d'optimisation
)
model.fit(X_train, y_train)
Tableau récapitulatif¶
| Modèle | Optimiseur(s) disponible(s) | Paramètre clé |
|---|---|---|
SGDClassifier/Regressor |
SGD | learning_rate, eta0 |
LogisticRegression |
lbfgs, sag, saga, newton-cg | solver |
MLPClassifier/Regressor |
adam, sgd, lbfgs | solver, learning_rate_init |
GradientBoosting* |
Gradient Boosting | learning_rate, n_estimators |
HistGradientBoosting* |
Histogram Gradient Boosting | learning_rate, max_iter |
Ridge |
svd, cholesky, sag, saga, lbfgs | solver |
Lasso/ElasticNet |
Coordinate Descent | max_iter, tol |
SVC/SVR |
SMO (Sequential Minimal Optimization) | max_iter, tol |
LassoCV/RidgeCV |
Cross-validation + solver | alphas, cv |
Les méthodes d'optimisation généralistes¶
Ces méthodes peuvent être appliquées à n'importe quel modèle, indépendamment de sa structure interne. Elles explorent l'espace des hyperparamètres de manière intelligente pour trouver la meilleure configuration.
Optimisation avec Optuna¶
Optuna est un framework d'optimisation bayésienne qui permet de trouver les meilleurs hyperparamètres de manière plus efficace qu'un GridSearchCV.
Principe général :
- Optuna utilise des algorithmes d'optimisation bayésienne (par défaut TPE - Tree-structured Parzen Estimator) pour explorer intelligemment l'espace des hyperparamètres
- Contrairement au GridSearch qui teste toutes les combinaisons, Optuna apprend des essais précédents pour orienter la recherche vers les régions les plus prometteuses
- Il supporte le pruning (arrêt anticipé des essais peu prometteurs) pour économiser du temps de calcul
Structure de base :
import optuna
from sklearn.model_selection import cross_val_score
# 1. Définir la fonction objectif à optimiser
def objective(trial):
# Définir l'espace de recherche des hyperparamètres
param1 = trial.suggest_float("param1", 0.01, 10.0, log=True) # paramètre continu (échelle log)
param2 = trial.suggest_int("param2", 1, 100) # paramètre entier
param3 = trial.suggest_categorical("param3", ["a", "b", "c"]) # paramètre catégoriel
# Créer et entrainer le modèle
model = MonModele(param1=param1, param2=param2, param3=param3)
# Retourner le score à optimiser (par défaut Optuna minimise)
score = cross_val_score(model, X_train, y_train, cv=5, scoring="accuracy")
return score.mean()
# 2. Créer une étude et lancer l'optimisation
study = optuna.create_study(direction="maximize") # ou "minimize" selon la métrique
study.optimize(objective, n_trials=100)
# 3. Récupérer les meilleurs paramètres
print(f"Meilleurs paramètres: {study.best_params}")
print(f"Meilleur score: {study.best_value}")
Exemple : optimisation d'un RandomForestClassifier
import optuna
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
def objective(trial):
# Espace de recherche des hyperparamètres
n_estimators = trial.suggest_int("n_estimators", 50, 500)
max_depth = trial.suggest_int("max_depth", 3, 20)
min_samples_split = trial.suggest_int("min_samples_split", 2, 20)
min_samples_leaf = trial.suggest_int("min_samples_leaf", 1, 10)
max_features = trial.suggest_categorical("max_features", ["sqrt", "log2", None])
# Création du modèle avec les hyperparamètres suggérés
model = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
max_features=max_features,
random_state=42,
n_jobs=-1
)
# Evaluation par cross-validation
score = cross_val_score(model, X_train, y_train, cv=5, scoring="accuracy")
return score.mean()
# Création de l'étude (on veut maximiser l'accuracy)
study = optuna.create_study(direction="maximize")
# Lancement de l'optimisation (100 essais)
study.optimize(objective, n_trials=100, show_progress_bar=True)
# Résultats
print(f"Meilleurs hyperparamètres: {study.best_params}")
print(f"Meilleure accuracy: {study.best_value:.4f}")
Entrainer le modèle final avec les meilleurs paramètres :
# Récupérer les meilleurs paramètres
best_params = study.best_params
# Entrainer le modèle final sur tout le jeu d'entrainement
best_model = RandomForestClassifier(**best_params, random_state=42, n_jobs=-1)
best_model.fit(X_train, y_train)
# Evaluer sur le jeu de test
print(f"Score sur le test set: {best_model.score(X_test, y_test):.4f}")
Visualisation des résultats :
# Historique de l'optimisation
optuna.visualization.plot_optimization_history(study)
# Importance des hyperparamètres
optuna.visualization.plot_param_importances(study)
# Relations entre hyperparamètres
optuna.visualization.plot_parallel_coordinate(study)
Types de suggestions disponibles :
| Méthode | Description | Exemple |
|---|---|---|
suggest_float |
Paramètre continu | trial.suggest_float("lr", 1e-5, 1e-1, log=True) |
suggest_int |
Paramètre entier | trial.suggest_int("n_layers", 1, 10) |
suggest_categorical |
Choix parmi une liste | trial.suggest_categorical("kernel", ["rbf", "linear"]) |
suggest_discrete_uniform |
Valeurs discrètes uniformes | trial.suggest_discrete_uniform("dropout", 0.1, 0.5, 0.1) |
A défaut, si vous n'avez pas d'autre méthodes d'optimisation: utilisez les méthode de type GridSearchCV¶
Si le modèle utilisé ne possède pas d'algorithme d'optimisation qui lui est applicable (par ex, la méthode des moindres carrés, applicables à la régression linéaire), on peut utiliser par défaut une méthode de type GridSearchCV
L'idée générale est de définir une grille de paramètre dans laquelle votre modèle sera entrainé avec des combinaisons de paramètres différentes, sur une partition cross validée de votre jeu de donnée d'apprentissage
On définit au préalable, une grille de paramètres à tester :
param_grid = {
"param_continu_1": [val1,val2,...]
"param_continu_2": [val1,val2,...]
"param_discret_1": ("val1","val2")
...
}
Puis on peut entraîne notre modèle, avec différentes stratégies pour le choix des combinaison des paramètres utilisés
Pour le GridSearchCV¶
On entraîne notre modèle de manière exhaustive pour chaque combinaison de paramètres de la grille
search = GridSearchCV(model, param_grid, refit=True, cv=5, ...)
search.fit(X_train, y_train)
Pour le HalvingSearchCV¶
Dans cette version, une sélection de paramètres (candidats) est entrainé de manière compétitive en plusieurs itérations. A chaque itération, seuls les meilleurs candidats sont sélectionnés et les ressources qui leur sont allouées pour chaque entraînement (en général des échantillons du dataset) sont multipliées par un facteur p.
Pour plus de détails voir le user guide
Il faudra fixer certains hyper-paramètres additionnels controllant le type de ressources, le nombre de candidats initial et le facteur utilisé :
search = HalvingGridSearchCV(model, param_grid, ressource='n_samples', n_candidates='exhaust', factor=3)
search.fit(X_train, y_train)
Pour le RandomizedSearchCV ou le HalvingRandomSearchCV¶
On entraîne notre modèle en tirant au hasard les paramètres continu de la grille
param_grid = {
"param_continu_1": scipy.stats.expon(loc=0, scale=100)# ici on tire au hasard des nombres entre 0 et 100 suivant une loi exponentielle
"param_discret_1": ("val1","val2")
...
}
search = RandomizedSearchCV(model, param_grid, refit=True, cv=5, random_state=42)
search.fit(X_train, y_train)
search = HalvingRandomSearchCV(model, param_grid, resource='n_samples', n_candidates='exhaust', factor=3)
search.fit(X_train, y_train)
Une fois l'optimisation terminée, on peut accéder à plusieurs attributs intéressants, en particulier les paramètres et le score de l'itération du modèle le plus performant:
search.best_params_
search.best_score_
ou encore au modèle ré-entrainé avec les meilleurs paramètres :
search.best_estimator_
Evaluer un modèle entraîné¶
une fois entrainé, il est possible de faire des prédictions et de calculer un score :
model.predict(X_test) # predictions sur le jeu de test
model.predict_proba(X_test) # uniquement pour certains modèles
model.score(X_test,y_test) # score calculé sur le jeu de test
la méthode .score calcule une métrique par défaut (accuracy pour la classification, $R^2$ pour la régression), mais il est possible de la changer, en appelant une métrique pré-definie dans scikit-learn:
par exemple si je souhaite utilise l'AUC :
from sklearn.metrics import auc
auc(X_test,y_test)
Représenter une courbe d'apprentissage¶
La courbe d'apprentissage est votre meilleur outil pour monitorer l'état de votre modèle dans le compromis biais/variance
train_sizes, train_scores, test_score = learning_curve(model, X, y)
plt.plot(train_sizes, np.mean(train_scores, axis=1), label="Training")
plt.plot(train_sizes, np.mean(test_scores, axis=1), label="Validation")
Vous pouvez utilisez la nouvelle classe LearningCurveDisplay pour tracer les learning curve plus facilement :
Il suffit de spécifier le modèle et des paramètres pour la représentation, le (.fit et le .predict) sont calculés automatiquement par scikit-learn :
params = {
"X": X_train,
"y": y_train,
"train_sizes": np.linspace(0.1, 1.0, 5),
"cv": ShuffleSplit(n_splits=50, test_size=0.2, random_state=0),
"score_type": "both",
}
display = LearningCurveDisplay.from_estimator(model, **params, ...)
La classe affiche automatiquement la courbe d'apprentissage mais vous pouvez appelez la méthode .plot() pour personnaliser votre graphique
Exemple avec un SVC entraîné sur le dataset digits:¶
On charge les données et entraîne un SVC
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1, random_state=42)
svc = SVC(kernel="rbf", gamma=0.001)
# attention dans la pratique je choisi ici les paramètres déja optimisés
import numpy as np
params = {
"X": X_train,
"y": y_train,
"train_sizes": np.linspace(0.1, 1.0, 5),
"cv": 5,
"score_type": "both",
}
from sklearn.model_selection import LearningCurveDisplay
LearningCurveDisplay.from_estimator(svc, **params);

Utiliser la validation croisée pour évaluer un modèle¶
Rappelons qu'il est toujours souhaitable d'évaluer vos modèles entraînés sur un partie cross validée du data set d'apprentissage X_train (si vous avez assez de données)
Pour obtenir un score moins sensible aux problème du compromis biais/variance, vous pouvez calculer un score cross validé avec la classe cross_validate ou cross_val_score :
cv_results = cross_validate(model, X, y, cv=...)
cv_results['test_score'] # la clé test score_enregistre le score de chaque entrainement cross-validé
Améliorer les données d'entrées¶
La réduction de dimensionalité¶
La réduction de dimensionalité consiste à diminuer le nombre de variables tout en conservant le maximum d'information. Elle est utile pour :
- Réduire le temps de calcul lors de l'entrainement
- Limiter le sur-apprentissage (curse of dimensionality)
- Visualiser des données en 2D ou 3D
- Éliminer le bruit et la redondance dans les données
Méthodes linéaires (basée sur la factorisation de matrices)¶
PCA (Principal Component Analysis) - La plus courante
from sklearn.decomposition import PCA
# Garder 95% de la variance expliquée
pca = PCA(n_components=0.95)
X_train_reduced = pca.fit_transform(X_train)
X_test_reduced = pca.transform(X_test)
# Ou spécifier le nombre de composantes
pca = PCA(n_components=10)
# Visualiser la variance expliquée
print(f"Variance expliquée par composante: {pca.explained_variance_ratio_}")
print(f"Variance totale expliquée: {pca.explained_variance_ratio_.sum():.2%}")
On trace généralement l'ébouli des valeurs propres pour détermnier les composantes susceptibles d'etre supprimées, sans trop de perte d'information :
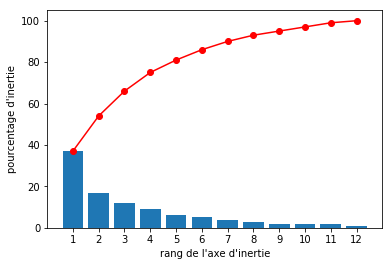
D'après Open Classroom
Autres méthodes linéaires :
from sklearn.decomposition import TruncatedSVD # Pour matrices creuses (sparse)
from sklearn.decomposition import FactorAnalysis # Analyse factorielle
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # Supervisée (LDA)
Méthodes non-linéaires (Manifold Learning)¶
Pour les données avec des structures non-linéaires complexes :
from sklearn.manifold import TSNE # Visualisation (non utilisable pour transform)
from sklearn.manifold import Isomap # Préserve les distances géodésiques
from sklearn.manifold import LocallyLinearEmbedding # LLE
import umap # UMAP (package externe, très populaire)
# t-SNE pour visualisation en 2D
tsne = TSNE(n_components=2, perplexity=30, random_state=42)
X_embedded = tsne.fit_transform(X) # Attention: pas de .transform() séparé
# UMAP (plus rapide que t-SNE, permet transform)
reducer = umap.UMAP(n_components=2, random_state=42)
X_embedded = reducer.fit_transform(X_train)
X_test_embedded = reducer.transform(X_test)
Tableau récapitulatif - Réduction de dimensionalité¶
| Méthode | Type | Usage principal | Peut transformer de nouvelles données |
|---|---|---|---|
PCA |
Linéaire | Usage général, preprocessing | Oui |
TruncatedSVD |
Linéaire | Données sparse (texte) | Oui |
LDA |
Linéaire supervisé | Classification | Oui |
t-SNE |
Non-linéaire | Visualisation uniquement | Non |
UMAP |
Non-linéaire | Visualisation + preprocessing | Oui |
Isomap |
Non-linéaire | Structures géométriques | Oui |
La sélection de features¶
Contrairement à la réduction de dimensionalité qui crée de nouvelles variables, la sélection de features conserve un sous-ensemble des variables originales. Elle permet de :
- Améliorer l'interprétabilité du modèle (on garde les vraies variables)
- Réduire le sur-apprentissage en éliminant les variables non pertinentes
- Accélérer l'entrainement et l'inférence
1. Méthodes par filtrage (Filter methods)¶
Sélection basée sur des tests statistiques indépendants du modèle :
from sklearn.feature_selection import SelectKBest, SelectPercentile
from sklearn.feature_selection import f_classif, f_regression, chi2, mutual_info_classif
# Garder les k meilleures features (selon le score F pour la classification)
selector = SelectKBest(score_func=f_classif, k=10)
X_train_selected = selector.fit_transform(X_train, y_train)
X_test_selected = selector.transform(X_test)
# Ou garder un pourcentage des features
selector = SelectPercentile(score_func=f_regression, percentile=50)
# Voir les scores et les features sélectionnées
print(f"Scores: {selector.scores_}")
print(f"Features sélectionnées: {selector.get_support()}")
| Fonction de score | Usage | Propriété testée |
|---|---|---|
f_classif |
Classification, variables continues | Teste séquentiellement le degré de dépendence linéaire entre deux variables |
f_regression |
Régression, variables continues | Teste séquentiellent l'effet d'un coefficient |
chi2 |
Classification, variables discètes & positives (ex: comptages) | Mesure l'indépendance entre deux variables |
mutual_info_classif |
Classification | Mesure les dépences non linéaire entre variables |
2. Méthodes basées sur le modèle (Embedded methods)¶
Utilisation de l'importance des features calculée par certains modèles :
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import Lasso
# Sélection basée sur l'importance des features d'un RandomForest
rf = RandomForestClassifier(n_estimators=100, random_state=42)
selector = SelectFromModel(rf, threshold='median') # ou threshold=0.01
X_train_selected = selector.fit_transform(X_train, y_train)
# Sélection basée sur les coefficients d'un Lasso (régularisation L1)
lasso = Lasso(alpha=0.01)
selector = SelectFromModel(lasso, threshold=1e-5)
X_train_selected = selector.fit_transform(X_train, y_train)
# Voir les features sélectionnées
feature_names = X_train.columns[selector.get_support()]
from sklearn.feature_selection import RFE, RFECV
from sklearn.ensemble import RandomForestClassifier
# RFE: Recursive Feature Elimination
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rfe = RFE(estimator=rf, n_features_to_select=10, step=1)
X_train_selected = rfe.fit_transform(X_train, y_train)
# RFECV: RFE avec cross-validation pour trouver le nombre optimal
rfecv = RFECV(estimator=rf, step=1, cv=5, scoring='accuracy')
rfecv.fit(X_train, y_train)
print(f"Nombre optimal de features: {rfecv.n_features_}")
print(f"Features sélectionnées: {rfecv.support_}")
4. Élimination de features à faible variance¶
Supprimer les features quasi-constantes :
from sklearn.feature_selection import VarianceThreshold
# Supprimer les features avec une variance < 0.01
selector = VarianceThreshold(threshold=0.01)
X_train_selected = selector.fit_transform(X_train)
# Pour des features binaires, supprimer celles avec >80% de la même valeur
# threshold = 0.8 * (1 - 0.8) = 0.16
selector = VarianceThreshold(threshold=0.16)
L'ingénierie de features (Feature Engineering)¶
L'ingénierie de features consiste à créer de nouvelles variables à partir des données existantes pour améliorer les performances du modèle. C'est souvent l'étape qui a le plus d'impact sur les performances finales.
1. Transformations numériques¶
Appliquer des transformations mathématiques pour capturer des relations non-linéaires :
from sklearn.preprocessing import PolynomialFeatures, SplineTransformer, PowerTransformer
# Créer des features polynomiales (x1, x2 -> x1, x2, x1², x2², x1*x2)
poly = PolynomialFeatures(degree=2, include_bias=False, interaction_only=False)
X_poly = poly.fit_transform(X_train)
# Splines pour capturer des relations non-linéaires locales
spline = SplineTransformer(n_knots=5, degree=3)
X_spline = spline.fit_transform(X_train)
# Transformation de puissance (normaliser des distributions asymétriques)
power = PowerTransformer(method='yeo-johnson') # ou 'box-cox' (valeurs > 0)
X_normalized = power.fit_transform(X_train)
2. Discrétisation (Binning)¶
Transformer des variables continues en catégories :
from sklearn.preprocessing import KBinsDiscretizer
# Discrétisation en intervalles égaux
discretizer = KBinsDiscretizer(n_bins=5, encode='ordinal', strategy='uniform')
X_binned = discretizer.fit_transform(X_train[['age']])
# Stratégies disponibles:
# - 'uniform': intervalles de même largeur
# - 'quantile': même nombre d'observations par bin
# - 'kmeans': bins basés sur le clustering
# Encodage disponible:
# - 'ordinal': entiers (0, 1, 2, ...)
# - 'onehot': one-hot encoding
# - 'onehot-dense': one-hot en array dense
3. Encodage des variables catégorielles¶
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder, LabelEncoder, TargetEncoder
# One-Hot Encoding (crée une colonne par catégorie)
ohe = OneHotEncoder(handle_unknown='ignore', sparse_output=False)
X_encoded = ohe.fit_transform(X_train[['ville']])
# Ordinal Encoding (pour variables ordonnées: petit < moyen < grand)
oe = OrdinalEncoder(categories=[['petit', 'moyen', 'grand']])
X_encoded = oe.fit_transform(X_train[['taille']])
# Target Encoding (encode par la moyenne de y par catégorie)
te = TargetEncoder(smooth='auto')
X_encoded = te.fit_transform(X_train[['ville']], y_train)
# Label Encoding (pour la variable cible uniquement)
le = LabelEncoder()
y_encoded = le.fit_transform(y_train)
| Encodeur | Usage | Remarques |
|---|---|---|
OneHotEncoder |
Variables nominales | Augmente la dimensionalité |
OrdinalEncoder |
Variables ordinales | Préserve l'ordre |
TargetEncoder |
Haute cardinalité | Risque de data leakage, utiliser avec CV |
LabelEncoder |
Variable cible (y) | Ne pas utiliser pour X |
4. Features temporelles¶
Extraction d'informations à partir de dates :
import pandas as pd
# Conversion en datetime
df['date'] = pd.to_datetime(df['date'])
# Extraction de composantes temporelles
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['day_of_week'] = df['date'].dt.dayofweek # 0=lundi, 6=dimanche
df['is_weekend'] = df['date'].dt.dayofweek >= 5 # booléen
df['quarter'] = df['date'].dt.quarter
df['week_of_year'] = df['date'].dt.isocalendar().week
# Features cycliques (pour capturer la périodicité)
import numpy as np
df['month_sin'] = np.sin(2 * np.pi * df['month'] / 12)
df['month_cos'] = np.cos(2 * np.pi * df['month'] / 12)
df['day_of_week_sin'] = np.sin(2 * np.pi * df['day_of_week'] / 7)
df['day_of_week_cos'] = np.cos(2 * np.pi * df['day_of_week'] / 7)
# Différences temporelles
df['days_since_event'] = (df['date'] - df['event_date']).dt.days
5. Features textuelles¶
Transformation de texte en vecteurs numériques :
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# Bag of Words (comptage de mots)
count_vec = CountVectorizer(
max_features=1000, # garder les 1000 mots les plus fréquents
stop_words='english', # supprimer les mots vides
ngram_range=(1, 2) # unigrams et bigrams
)
X_bow = count_vec.fit_transform(corpus)
# TF-IDF (Term Frequency - Inverse Document Frequency)
tfidf = TfidfVectorizer(
max_features=1000,
stop_words='english',
ngram_range=(1, 2),
min_df=2, # ignorer les mots dans moins de 2 documents
max_df=0.95 # ignorer les mots dans plus de 95% des documents
)
X_tfidf = tfidf.fit_transform(corpus)
# Features de longueur et statistiques simples
df['text_length'] = df['text'].str.len()
df['word_count'] = df['text'].str.split().str.len()
df['avg_word_length'] = df['text'].apply(lambda x: np.mean([len(w) for w in x.split()]))
Tableau récapitulatif - Ingénierie de features¶
| Technique | Classe sklearn | Usage |
|---|---|---|
| Features polynomiales | PolynomialFeatures |
Relations non-linéaires entre variables |
| Splines | SplineTransformer |
Relations locales non-linéaires |
| Transformation de puissance | PowerTransformer |
Normaliser distributions asymétriques |
| Discrétisation | KBinsDiscretizer |
Transformer continu → catégoriel |
| One-Hot Encoding | OneHotEncoder |
Variables nominales |
| Target Encoding | TargetEncoder |
Haute cardinalité |
| Bag of Words | CountVectorizer |
Texte → vecteurs (comptage) |
| TF-IDF | TfidfVectorizer |
Texte → vecteurs (pondéré) |
Bonnes pratiques :
- Toujours apprendre les transformations sur le train set et appliquer sur le test set
- Utiliser les pipelines pour enchaîner les transformations
- Tester l'impact de chaque nouvelle feature sur les performances
- Attention au data leakage avec le target encoding (utiliser la cross-validation)
Pipelines dans scikit-learn¶
Ce sont des objets permettant d'implémenter une chaîne de traitements modularisés qui facilteront l'automatisation

L'objet pipeline est fabriqué de telle sorte qu'il hérite des méthodes du dernier objet de la séquence:
- pour les Transformers: les méthodes
fitettransform - pour les Modeles: les méhtodes
fit,predict,score, ...
- A l'éxecution du
.fitde la pipeline, la méthodes.fit_transformde chaque transformer est appelée, pour le modèle, seule la méthode.fitest appelée - les outputs des transformers et celle du modèle sont enregistrés dans la mémoire de la pipeline
- A l'éxécution de la méthode prédict, seule les méthodes
.transformdes transformers sont appelées, et la méthode.predictpour le modèle
Cette construction évite de faire du data leakage :)
Avantages
- rend votre workflow plus facilement lisible et compréhensive
- facilite l'automatisation des itérations de votre chaîne de traitement
- rend votre travail plus facilement reproductible et déployable
Exemples d'utilisation¶
Nous utilisons un dataset pour la prédiction d'assurances de santé en fonction de diverses variables
import pandas as pd
import numpy as np
data = pd.read_csv("https://filedn.eu/lefeldrXcsSFgCcgc48eaLY/datasets/regression/data_insurance.csv")
data.head()
X = data.drop(columns='charges')
y = data['charges']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
Nous allons réaliser les traitements suivants, dans une même pipeline:
- imputation des valeurs manquantes
- scaling des features numériques
- encodage des features catégorielles
- entraintement du modèle
Imputation et scaling¶
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
pipe = Pipeline([
('imputer', SimpleImputer()),
('scaler', StandardScaler())
])
pipe.fit_transform(X_train[['age']])[0:3]
# accéder aux étapes
pipe[0]
pipe['imputer']
Son rôle est d'appliquer des traitements sur des colonnes spécifiques qui vont se faire en parallèle
Dans cet exemple, cela va nous servir à faire l'encodage des features (en one-hot-encoder)
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
# Imputation et scaling des variables numériques
num_transformer = Pipeline([
('imputer', SimpleImputer()),
('scaler', StandardScaler())])
# Encodage de la feature catégorielle
cat_transformer = OneHotEncoder(handle_unknown='ignore')
# On parallelise les deux traitements "num_transformer" et "cat_transformer"
preprocessor = ColumnTransformer([
('num_tr', num_transformer, ['age','bmi']),
('cat_tr', cat_transformer, ['smoker', 'region'])])
# visualisation des pipelines en HTML
from sklearn import set_config; set_config(display='diagram')
preprocessor
X_train_transformed = preprocessor.fit_transform(X_train)
display(X_train.head(3))
display(pd.DataFrame(X_train_transformed).head(3))
preprocessor.feature_names_in_
# bug dans la version 1.0.2: le transformer SimpleImputer n'a pas encore de méthode get_feature_names_out
SimpleImputer.get_feature_names_out = (lambda self, names=None: self.feature_names_in_)
# Nouveau dans scikit-learn 1.0.2
preprocessor.get_feature_names_out()
pd.DataFrame(X_train_transformed,columns = [preprocessor.get_feature_names_out()]).head()
la variable 'children' n'a pas été traitée par le ColumnTransformer, par défaut elle n'est pas renvoyée
preprocessor
Comme elle n'a pas besoin d'être encodée, on peut la renvoyer telle quelle avec reminder='passthrough'
preprocessor = ColumnTransformer([
('num_tr', num_transformer, ['age','bmi']),
('cat_tr', cat_transformer, ['region','smoker'])],
remainder='passthrough')
preprocessor
pd.DataFrame(preprocessor.fit_transform(X_train)
,columns = [preprocessor.get_feature_names_out()]).head(3)
On peut également appliquer dans une pipeline des fonctions quelconque en les encapsulant grace à FunctionTransformer.
Créons un Transformer pour arrondir les données dans notre dataframe
from sklearn.preprocessing import FunctionTransformer
rounder = FunctionTransformer(lambda array: np.round(array, decimals=2))
rounder.get_feature_names_out = (lambda self, names=None: self.feature_names_in_)
num_transformer = Pipeline([
('imputer', SimpleImputer()),
('scaler', StandardScaler()),
('rounder', rounder)])
preprocessor = ColumnTransformer([
('num_tr', num_transformer, ['bmi', 'age']),
('cat_tr', cat_transformer, ['region', 'smoker'])],
remainder='passthrough')
preprocessor
pd.DataFrame(preprocessor.fit_transform(X_train)).head(3)
Permet d'appliquer des transformers en parallèle et de concatener l'output de chaque transformer à notre data set
Cela peut être utile pour créer de nouvelles features et les ajouter au dataset:
from sklearn.pipeline import FeatureUnion
# On crée une nouvelle variable en en multipliant deux
bmi_age_ratio = FunctionTransformer(lambda df: pd.DataFrame(df["bmi"] / df["age"]))
union = FeatureUnion([
('preprocess', preprocessor), # colonnes 0-8
('bmi_age_ratio', bmi_age_ratio) # nouvelle colonne 9
])
union
Quelques raccourcis¶
from sklearn.pipeline import make_pipeline
from sklearn.pipeline import make_union
from sklearn.compose import make_column_transformer
Pipeline([
('my_name_for_imputer', SimpleImputer()),
('my_name_for_scaler', StandardScaler())
])
# est équivalent à:
make_pipeline(SimpleImputer(), StandardScaler())
num_transformer = make_pipeline(SimpleImputer(), StandardScaler())
cat_transformer = OneHotEncoder()
preproc_basic = make_column_transformer((num_transformer, ['age', 'bmi']),
(cat_transformer, ['smoker', 'region']),
remainder='passthrough')
preproc_full = make_union(preproc_basic, bmi_age_ratio)
preproc_full
On aurait pu aussi utiliser make_column_selector pour sélectionner les colonnes à traiter par leur dtype
X_train.dtypes
from sklearn.compose import make_column_selector
num_col = make_column_selector(dtype_include=['float64'])
cat_col = make_column_selector(dtype_include=['object','bool'])
num_transformer = make_pipeline(SimpleImputer(), StandardScaler())
num_col = make_column_selector(dtype_include=['float64'])
cat_transformer = OneHotEncoder()
cat_col = make_column_selector(dtype_include=['object','bool'])
preproc_basic = make_column_transformer(
(num_transformer, num_col),
(cat_transformer, cat_col),
remainder='passthrough')
preproc_full = make_union(preproc_basic, bmi_age_ratio)
preproc_full
Rajoutons l'entrainement du modèle à notre pipeline¶
Rajout d'un modèle Ridge¶
from sklearn.linear_model import Ridge
# Pipeline de preprocessing
num_transformer = make_pipeline(SimpleImputer(), StandardScaler())
cat_transformer = OneHotEncoder()
preproc = make_column_transformer(
(num_transformer, make_column_selector(dtype_include=['float64'])),
(cat_transformer, make_column_selector(dtype_include=['object','bool'])),
remainder='passthrough')
# Ajout du modèle
pipe = make_pipeline(preproc, Ridge())
pipe
Entrainement et résultats¶
# Preprocessing et entrainement du modèle
pipe.fit(X_train,y_train)
# Prédictions
pipe.predict(X_test.iloc[0:2])
# Score
print(f"Score cross-validé moyen sur le train set: {cross_val_score(pipe, X_train, y_train, cv=5, scoring='r2').mean()}")
print(f"Score sur le test set:{pipe.score(X_test,y_test)}")
Grid Search dans une pipeline¶
On veut vérifier quelle combinaison des paramètres du préprocessing et de l'entrainement donne les meilleurs résultats
On peut pour cela faire un GridSearch sur n'importe quelle composant de la pipeline, avec la syntaxe :
nom_etape__nom_transformer__nom_hyperparam
from sklearn.model_selection import GridSearchCV
# On peut afficher tous les paramètres de tout les composants de la pipeline
pipe.get_params().keys()
pipe.get_params()['columntransformer']
grid_search = GridSearchCV(
pipe,
param_grid={
# grille des hyper paramètres à tester
'columntransformer__pipeline__simpleimputer__strategy': ['mean', 'median'],
'ridge__alpha': [0.1, 0.5, 1, 5, 10]},
cv=5,
scoring="r2")
# entraine toute la pipeline et la ré-entraine avec les meilleurs paramètres trouvés
grid_search.fit(X_train, y_train)
grid_search.best_params_
On enregistre la pipeline entrainée avec les meilleurs estimateurs:
pipe_tuned = grid_search.best_estimator_
Mettre des transformations en cache pour economiser du temps de calcul¶
Certaines opérations d'une pipeline peuvent être mise en cache afin de ne pas être recalculés:
- les calculs des hyperparmètres du modèle
from tempfile import mkdtemp
from shutil import rmtree
# Create a temp folder
cachedir = mkdtemp()
# Instantiate the pipeline with cache parameter
pipe = make_pipeline(preproc, Ridge(), memory=cachedir)
# Clear the cache directory after the cross-validation
rmtree(cachedir)
Débuger sa pipeline¶
# acceder a chacun des composants
pipe_tuned.named_steps.keys()
# vérifier une étape intermédiaire
pipe_tuned.named_steps["columntransformer"].fit_transform(X_train).shape
Etapes finales¶
Exporter sa pipeline entrainée¶
Une fois votre chaine de traitement exécutée, vous avez interêt à sauvegarder l'ensemble de ses traitements. Elle peut être ensuite rechargée, pour faire d'autres iterations, ou la déployer.
Par exemple, je peux sauvegarder ma pipeline complète de traitement et la recharger plus tard pour faire des prédictions
# le module pickle de python permet de sauvegarder n'importe quel objet
import pickle
# spécifier le path pour le fichier final
from pathlib import Path
import os
export_path = Path("/home/nico/code/demos/")
os.path.join(export_path,'test')
# exporter la pipeline
export_path = "/home/nico/code/demos/"
with open(os.path.join(export_path,"pipeline.pkl"), "wb") as file:
pickle.dump(pipe_tuned, file)
# recharger la pipeline
my_pipeline = pickle.load(open(os.path.join(export_path,"pipeline.pkl"),"rb"))
# faire une prédiction avec la pipeline entrainée
my_pipeline.score(X_test, y_test)