Leçon: Introduction au Traitement du langage Naturel (TALN) ou (NLP)¶
Ressources¶
Il s'agit d'une librairie de référence, très utilisée pour le TALN, comprenant des ressources pour différentes langues.
pip install --user -U nltk
Attention pour l'utilisation de certains modules il vous faudra télécharger des données supplémentaires, par exemple vous pouvez télécharger le subset d'utilisation la plus courante:
import nltk
nltk.download('popular')
Il s'agit d'une librairie spécialisée dans le topic modeling. Elle propose en autre des implémentations d'embedding connus comme word2vec
Il s'agit d'un framework très complet et à la pointe de la recherche en TALN puisqu'il intégre les dernières découvertes comme les transformers. Il est organisé comme un écosystème permettant de créer des chaînes de traitement industrialisables, du prototype à la production.
Le framework Hugging Face¶
Tout comme Spacy, il s'agit d'un framework très complet et haut niveau pour une pratique industrialisable du TALN. Il s'illustre particulièrement dans les modèles pré-entrainés à l'état de l'art qu'ils proposent pour différents types de tâche
Les pré-traitements "standart" spécifiques au texte¶
Comme dans toutes les étapes de traitements, il n'y a pas de recette invariable, les pré-traitements à appliquer dépendront beaucoup des caractéristiques du corpus de document ainsi que de la tâche. Néanmoins, il est courant d'avoir besoin d'appliquer certains traitements standart:
- gérer la casse
- gérer les caractères spéciaux : nombres, punctuations, émoticonnes, ...
- enlever les stopwords
- tokenisation
- racinisation / lemmatisation
- ...
Lorsque l'on souhaite faire de l'apprentissage supervisé, il est parfois nécessaire de labeliser les données en les annontant (pour la classification, la traduction, ...)
Gestion de la casse¶
Deux mots ayant une casse différente seront considérés comme des mots différents dans la plupart des représentations. Si la casse, par ex les majuscules, n'apporte pas d'information supplémentaires, il vaut mieux alors uniformiser la casse:
text = "Linux systems are used by less than 2% of people while 55% of developpers are using Linux. Maybe people should use it more often ;-) "
text = text.lower()
text
'linux systems are used by less than 2% of people while 55% of developpers are using linux. maybe people should use it more often ;-) '
Dans certaines tâches, comme Named Entity Recognition, conserver les majuscules peut être utile
Gestion des caractères spéciaux¶
Enlever les nombres¶
text = ''.join(word for word in text if not word.isdigit())
text
'linux systems are used by less than % of people while % of developpers are using linux. maybe people should use it more often ;-) '
Garder les nombres peut s'avérer une information utile dans certains cas (par exemple l'extraction de dates)
Enlever la ponctuation¶
Dans beaucoup de tâches la ponctuation n'apporte pas d'information pertinente pour la tâche. Même en considérant la possibilité de la garder, il faut faire attention au fait que tous les textes ne respectent pas forcement leur format (ex : réseaux sociaux). C'est pourquoi on choisi souvent de la supprimer:
import string
string.punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
for punctuation in string.punctuation:
text = text.replace(punctuation, '')
text
'linux systems are used by less than of people while of developpers are using linux maybe people should use it more often '
Dans certaines tâches,comme l'analyse de sentiment, les ponctuations particulières comme les ! peuvent être informatives. On peut choisir alors de les garder
Caractères ou motifs particuliers¶
Comme les émoticonnes, certains caractères ou motifs peuvent être informatifs pour une tâche données, par exemple l'analyse de sentiments, ou non informatifs. Il est souvent utiles de pouvoir les extraires pour créer une nouvelle variable ou simplement les supprimer.
On peut utiliser:
- les expressions régulières : par exemple pour extraires des adresses e-mail
- des modules particuliers: comme hugging face pour détecter les émoticonnes,
- ...
Enlever les stopwords¶
Les stopwords sont des mots qui appraissent fréquemment dans les corpus et qui sont généralement peu informatifs (articles; de, le, la, pronoms: elle, lui, ...)
Plusieurs librairies comme NLTK proposent des collections de stopwords dans différentes langues, qui ont été construites par des linguististes spécifiquement pour le traitement automatique du langage
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
stop_words
{'a',
'about',
'above',
'after',
'again',
'against',
'ain',
'all',
'am',
'an',
'and',
'any',
'are',
'aren',
"aren't",
'as',
'at',
'be',
'because',
'been',
'before',
'being',
'below',
'between',
'both',
'but',
'by',
'can',
'couldn',
"couldn't",
'd',
'did',
'didn',
"didn't",
'do',
'does',
'doesn',
"doesn't",
'doing',
'don',
"don't",
'down',
'during',
'each',
'few',
'for',
'from',
'further',
'had',
'hadn',
"hadn't",
'has',
'hasn',
"hasn't",
'have',
'haven',
"haven't",
'having',
'he',
'her',
'here',
'hers',
'herself',
'him',
'himself',
'his',
'how',
'i',
'if',
'in',
'into',
'is',
'isn',
"isn't",
'it',
"it's",
'its',
'itself',
'just',
'll',
'm',
'ma',
'me',
'mightn',
"mightn't",
'more',
'most',
'mustn',
"mustn't",
'my',
'myself',
'needn',
"needn't",
'no',
'nor',
'not',
'now',
'o',
'of',
'off',
'on',
'once',
'only',
'or',
'other',
'our',
'ours',
'ourselves',
'out',
'over',
'own',
're',
's',
'same',
'shan',
"shan't",
'she',
"she's",
'should',
"should've",
'shouldn',
"shouldn't",
'so',
'some',
'such',
't',
'than',
'that',
"that'll",
'the',
'their',
'theirs',
'them',
'themselves',
'then',
'there',
'these',
'they',
'this',
'those',
'through',
'to',
'too',
'under',
'until',
'up',
've',
'very',
'was',
'wasn',
"wasn't",
'we',
'were',
'weren',
"weren't",
'what',
'when',
'where',
'which',
'while',
'who',
'whom',
'why',
'will',
'with',
'won',
"won't",
'wouldn',
"wouldn't",
'y',
'you',
"you'd",
"you'll",
"you're",
"you've",
'your',
'yours',
'yourself',
'yourselves'}
La tokenization¶
Cette opération consiste à segmenter chaque phrase en tokens, un string représentant un élément contenant du sens: par exemple on définit souvent les tokens comme des mots, ou des associations de $n$ mots, les n-grams
from nltk.tokenize import word_tokenize
word_tokens = word_tokenize(text)
word_tokens
['linux', 'systems', 'are', 'used', 'by', 'less', 'than', 'of', 'people', 'while', 'of', 'developpers', 'are', 'using', 'linux', 'maybe', 'people', 'should', 'use', 'it', 'more', 'often']
On en profite souvent au passage pour supprimer les stopwords de la liste des tokens:
text = [w for w in word_tokens if not w in stop_words]
text
['linux', 'systems', 'used', 'less', 'people', 'developpers', 'using', 'linux', 'maybe', 'people', 'use', 'often']
Ce processus consiste à réduire les tokens à leur racine morphologique: des mots partageant la même racine seront remplacés par leur racine:
Playing, plays, played → play
text
['linux', 'systems', 'used', 'less', 'people', 'developpers', 'using', 'linux', 'maybe', 'people', 'use', 'often']
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
stemmed = [stemmer.stem(word) for word in text]
stemmed
['linux', 'system', 'use', 'less', 'peopl', 'developp', 'use', 'linux', 'mayb', 'peopl', 'use', 'often']
Dans le domainee du TALN, la lemmatisation consiste à determiner le lemme d'un mot en se basant sur son sens. Au contraire du stemming, la lemmatisation depend de la nature du mot (que l'on peut determiner par le part of speech tagging) ainsi que du contexte du mot dans la phrase ou par rapport aux autres phases voisines dans le document.
am, are, is → be
cars, car's, car → car
text
['linux', 'systems', 'used', 'less', 'people', 'developpers', 'using', 'linux', 'maybe', 'people', 'use', 'often']
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatized = [lemmatizer.lemmatize(word) for word in text]
text = lemmatized
lemmatized
['linux', 'system', 'used', 'le', 'people', 'developpers', 'using', 'linux', 'maybe', 'people', 'use', 'often']
Il s'agit d'une représentation très simple des données visant à encoder les tokens, en fonction de leur fréquence d'apparition dans les documents du corpus.
Avantages & Inconvénients¶
Inconvénients
- Ne prends pas finement en compte les interactions entre les tokens et donc peu d'éléments de contexte
- L'importance de certains mots fréquents mais peu informatifs tend à produire une représentation biaisée
- Augmente fortement la dimensionalité du dataset ré-eoncodé
Avantages
- Simple à comprendre
- Agnostique du langage étudié
Bien qu'elle soit très simple, il s'agit souvent du point de départ pour de nombreux traitements et analyses dans les chaînes de traitement en TALN !
Vectorisation simple¶
Ce processus consiste à transformer une collection de documents en vecteurs de features numérique. Il est implémenté dans scikit-learn par la classe CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third',
'this'], dtype=object)
X est encodée sous forme de sparse matrix, pour économiser de la RAM:
X
<4x9 sparse matrix of type '<class 'numpy.int64'>' with 21 stored elements in Compressed Sparse Row format>
Attention, On peut repasser X au format numpy array, mais je vous conseille de ne le faire que pour une visualisation temporaire, pas dans votre chaîne de traitement
print(X.toarray())
[[0 1 1 1 0 0 1 0 1] [0 2 0 1 0 1 1 0 1] [1 0 0 1 1 0 1 1 1] [0 1 1 1 0 0 1 0 1]]
import pandas as pd
pd.DataFrame(data = X.toarray(), columns = vectorizer.get_feature_names_out())
| and | document | first | is | one | second | the | third | this | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
| 1 | 0 | 2 | 0 | 1 | 0 | 1 | 1 | 0 | 1 |
| 2 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
| 3 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
Vectorisation Term Frequency - Inverse Document Frequency (Tf-Idf)¶
Il s'agit d'un variation de la vectorisation simplement basée sur la fréquence d'apparition des tokens dans chaque document. On ajoute en plus dans le calcul un terme de pondération visant à prendre en compte la fréquence des tokens dans le corpus total :
TF-IDF(t,d) = TF(t,d) x IDF(t)
avec $IDF(t) = log(\frac{1+n}{1+df(t)}+1)$
- n : nombre total de documents
- 𝑇𝐹(𝑡,𝑑): Frequence du token t dans le document d
- DF(t) : Frequence du token t dans tous les documents
Les paramètres de vectorisation de CountVectoriser et TfIdfVectorizer¶
Le paramètre ngram_range¶
Vectorisation en considérant des mots (1-grams) comme tokens:
pd.DataFrame(data = X.toarray(), columns = vectorizer.get_feature_names_out())
| and | document | first | is | one | second | the | third | this | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
| 1 | 0 | 2 | 0 | 1 | 0 | 1 | 1 | 0 | 1 |
| 2 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
| 3 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
Dans cet exemple, on vectorise uniqument des paires de mots, des bi-grams (2-grams):
bigrams = CountVectorizer(analyzer='word', ngram_range=(2, 2))
X_bigrams = bigrams.fit_transform(corpus)
pd.DataFrame(data = X_bigrams.toarray(), columns = bigrams.get_feature_names_out())
| and this | document is | first document | is the | is this | second document | the first | the second | the third | third one | this document | this is | this the | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
Le paramètre max_df¶
Il permet d'exclure certains mots trop fréquents du corpus du processus de vectorisation en fonction d'un seuil
vectorizer = CountVectorizer(max_df=0.8)
X = vectorizer.fit_transform(corpus)
pd.DataFrame(data = X.toarray(), columns = vectorizer.get_feature_names_out())
| and | document | first | one | second | third | |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| 1 | 0 | 2 | 0 | 0 | 1 | 0 |
| 2 | 1 | 0 | 0 | 1 | 0 | 1 |
| 3 | 0 | 1 | 1 | 0 | 0 | 0 |
Le paramètre min_df¶
Il permet d'exclure certains mots trop peu fréquents du corpus du processus de vectorisation en fonction d'un seuil
vectorizer = CountVectorizer(min_df=0.3)
X = vectorizer.fit_transform(corpus)
pd.DataFrame(data = X.toarray(), columns = vectorizer.get_feature_names_out())
| document | first | is | the | this | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 1 | 1 |
| 1 | 2 | 0 | 1 | 1 | 1 |
| 2 | 0 | 0 | 1 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 | 1 |
Les words embedding / Distributional Semantic Models¶
On peut voir le word embedding comme une extension de la représentation Bag-of-word
Il s'agit d'appliquer des méthodes d'embedding (plongements) sur un corpus de texte afin de représenter les mots présents dans ce corpus (espace de départ) sous forme d'espace vectoriel multi-dimensionnel (espace d'arrivée).
Le type de plongement est souvent choisi spécifiquement pour faire émerger, dans l'espace d'arrivée, la notion de sématique: pour chaque mot, une partie du contexte sémantique est capturé en prenant en compte les mots voisins dans le calcul
Intérêt¶
Capturer la similarité sémantique¶
L'intérêt principal de ce type de représentation est de capturer la similarité sémantique entre les mots: des mots similaires auront tendance à être représentés par des points proches dans l'espace vectoriel d'arrivée:
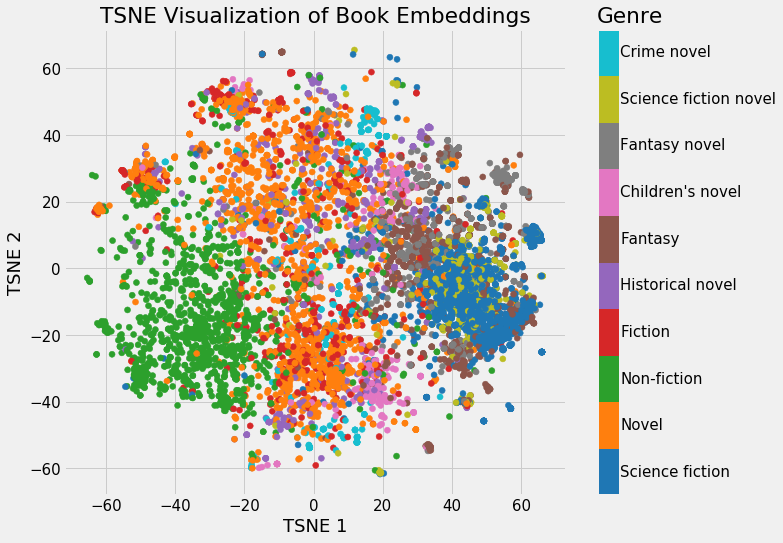
Capturer des relations entre les mots¶
Comme chaque mot est représenté par un vecteur, il est possible de faire des opérations arithmetiques sur ces vecteurs ! Les propriétés de l'embedding permettent ainsi de faire apparaître des relations entre les vecteurs de mots, comme capturer des analogies entre les mots
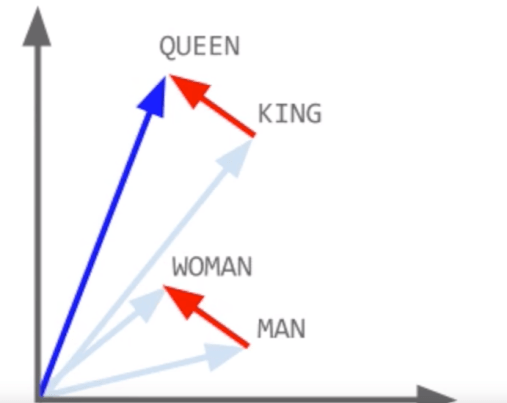
Dans cet embedding 2D, les vecteurs en rouge semble égaux, c'est à dire qu'on peut définir l'anlogie suivante:
V(Queen) - V(King) = V(Woman) - V(Man)
D'ou on peut déduire : V(Queen) - V(King) + V(Man) = V(Woman)
Quelques méthodes d'embedding "généralistes"¶
- Neural Network Language model: Il s'agit d'un réseau de neurone simple (souvent à une couche cachée) dans lequel on passe en entrée des mots vectorisés (par exemple par la représentation Bag-of-word) dans lequel la couche cachée joue le rôle d'embedding

- Latent Semantic Analysis (LSA) : Cette méthode utilise une décomposition de matrice, la Singular Value Decomposition tronquée (tSVD), sous forme de plongement linéaire, pour fabriquer les vecteurs de base d'un nouvel espace (les composantes)
- ...
Word2Vec¶
C'est un algorithme très populaire, il est implémenté dans plusieurs frameworks.
Il a été une des premières méthodes à mettre en avant les opérations arithmétiques sur les vecteurs de mots !
Le principe réside dans le fait d'utiliser une astuce dans laquelle on entraine un réseau de neurone (avec une seule couche cachée) sur une fausse tâche inutile.
L'intếret est de d'apprendre un embbeding dense, par la couche cachée qui aura été "forcée" à apprendre une représentation condensée du corpus de texte, en prenant en compte le contexte, représenté par les mots voisins. La représentation ainsi apprise contient des relations sémantiques basées sur les co-occurences des mots dans le dataset.
L'influence des mots voisins est réglée par un hyper-paramètre window size qui définit le nombre de mot voisins avant et après le mot cible qui représenteront le contexte.
Augmenter la taille de window size peut permettre de capturer plus de contexte (au risque d'utiliser des mots voisins non pertinents comme contexte) alors que diminuer la taille de window size incluera moins de contexte dans la représentation apprise
Il existe deux approches différentes pour entrainer ce réseau de neurone, qui différe sur la facon d'utiliser les mots voisins comme contexte:
Continous Bag-of-words (CBoW)¶
Dans cette approche, le réseau de neurone prédit le mot courant à partir d'une fenêtre de mots voisins et l'ordre des mots contenus dans cette fenêtre n'influence pas la prédiction (approche Bag-of-word)
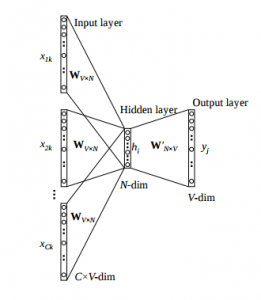
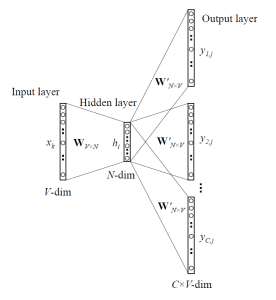
Skip-gram¶
Dans cette approche, le réseau de neurone utilise le mot cible pour prédire les mots voisins de la fenêtre et accordera plus de poids aux mots proches de la fenêtre que ceux plus lointain
Exemple de Word2Vec avec gensim¶
Import des modules et du vocabulaire (ici common_texts)
from gensim.models import Word2Vec
from gensim.test.utils import common_texts
common_texts
[['human', 'interface', 'computer'], ['survey', 'user', 'computer', 'system', 'response', 'time'], ['eps', 'user', 'interface', 'system'], ['system', 'human', 'system', 'eps'], ['user', 'response', 'time'], ['trees'], ['graph', 'trees'], ['graph', 'minors', 'trees'], ['graph', 'minors', 'survey']]
Import du modèle Word2Vec pré-entrainé :
model = Word2Vec(sentences=common_texts, vector_size=100, window=5, min_count=1, workers=4)
On peut ensuite calculer des vecteurs de mots :
model.wv['computer']
array([-0.00515774, -0.00667028, -0.0077791 , 0.00831315, -0.00198292,
-0.00685696, -0.0041556 , 0.00514562, -0.00286997, -0.00375075,
0.0016219 , -0.0027771 , -0.00158482, 0.0010748 , -0.00297881,
0.00852176, 0.00391207, -0.00996176, 0.00626142, -0.00675622,
0.00076966, 0.00440552, -0.00510486, -0.00211128, 0.00809783,
-0.00424503, -0.00763848, 0.00926061, -0.00215612, -0.00472081,
0.00857329, 0.00428459, 0.0043261 , 0.00928722, -0.00845554,
0.00525685, 0.00203994, 0.0041895 , 0.00169839, 0.00446543,
0.0044876 , 0.0061063 , -0.00320303, -0.00457706, -0.00042664,
0.00253447, -0.00326412, 0.00605948, 0.00415534, 0.00776685,
0.00257002, 0.00811905, -0.00138761, 0.00808028, 0.0037181 ,
-0.00804967, -0.00393476, -0.0024726 , 0.00489447, -0.00087241,
-0.00283173, 0.00783599, 0.00932561, -0.0016154 , -0.00516075,
-0.00470313, -0.00484746, -0.00960562, 0.00137242, -0.00422615,
0.00252744, 0.00561612, -0.00406709, -0.00959937, 0.00154715,
-0.00670207, 0.0024959 , -0.00378173, 0.00708048, 0.00064041,
0.00356198, -0.00273993, -0.00171105, 0.00765502, 0.00140809,
-0.00585215, -0.00783678, 0.00123305, 0.00645651, 0.00555797,
-0.00897966, 0.00859466, 0.00404816, 0.00747178, 0.00974917,
-0.0072917 , -0.00904259, 0.0058377 , 0.00939395, 0.00350795],
dtype=float32)
Et même obtenir les vecteurs de mots les plus similaires :
model.wv.most_similar('computer', topn=3)
[('system', 0.21617139875888824),
('survey', 0.04468922317028046),
('interface', 0.015203381888568401)]
Ou les différences de vecteurs de mots :
# vecteur correspondant à human - interface
model.wv.most_similar(['human','interface'], topn=3)
[('response', 0.14778193831443787),
('eps', 0.12549911439418793),
('system', 0.09567634016275406)]
Doc2Vec¶
Il s'agit d'une extension du modèle Word2Vec dans laquelle l'embedding apprend une représentation des documents dans le corpus:
Alors que Word2Vec crée comme feature un vecteur pour chaque mot dans le corpus, Doc2Vec crée comme feature un vecteur pour chaque document dans le corpus
Alors que la méthode Word2Vec utilise des informations locales uniquement (réglées par la window size) pour apprendre son embedding, GloVe utilise des des statistiques globales supplémentaires, apprise sur tout le corpus, pour apprendre son embedding.
Ces statistiques globales supplémentaires, sont apprises en utilisant la LSA sur une matrice composée en ligne, de la co-occurence des mots et en colonne du contexte des mots

Quelques algorithmes utilisés en TALN (avec Bag of word ou des words embedding)¶
Dans des tâches de classification: par ex filtre anti spam¶
- Naives Bayes
- Régression Logistique
- ...
Tâche de topic modeling:¶
- Latent Dirichlet Allocation
- RNN
Tâche de production de texte¶
- RNN
- Les Transformers
Quel word embedding utiliser ?¶
- Utiliser des embedding pré-entrainés sur de vastes corpus de texte (souvent en anglais) : utile lorsque vous utiliser un vocabulaire assez générique dans la langue que vous souhaitez étudié
- Entrainer son propre embedding : utile lorsque le langage étudié et/ou le vocabulaire est spécifique
Les Transformers¶
Le Transformer est un modèle de deep learning relativement récent (imaginés à partir de 2014 mais mis en place plus tardivement) qui propose une innovation par rapport aux modèles dominants utilisés jusqu'a alors, à savoir les réseaux de neurones récurrents comme les LSTM
La particularité des Transformers est de ne pas utiliser la structure de ces réseaux réccurent, mais des mécanismes d'attention.
Ces derniers réseaux sont parmi les plus gros jamais imaginés en deep learning (en nombre de paramètres) ! Ils ont été entrainés de manière non supervisée à prédire le prochain mot dans un texte, sur de très gros corpus
On peut citer les modèles Bert de Google et GPT-2 de OpenAI qui sont capables une fois entrainés de répondre à plusieurs tâches de TALN !!!
- générer du texte
- répondre à des questions
- faire de la traduction
Ces modéles ont été libérés en open source (notemment dans le framework Huggin Face) et peuvent être utilisés dans leur version pré-entrainée.
OpenAI a récemment publié la nouvelle version de son célèbre transformer, GPT-3, qui n'est pour l'instant accessible que par des API payantes.
Sources¶
- La page de documentation dédiée à l'extraction de feature textuelles de sckit-learn
- Article de Devopedia sur le word embedding: bon article bien résumé et référencé qui contient également des exemples de code
- Cet article du blog Towards Data Science consacré aux word embeddings: permet de comprendre leur construction
- Cet article du blog Towards Data Science consaccé aux word embeddings: recense et explique différents algorithmes historiques
- Cet article de blog résume bien les principes basiques des Transformers