Leçon: Introduction à la mise en production d'une application en data science¶
Intérêt de packager son projet¶
Code plus facilement réutilisable et installable:¶
- Permet d'encapsuler son code sous forme de modules empaquetés dans un package --> reprend les standart de python
- Facilite la lecture et la revue de votre code et la contribution (collegues, open source, ...)
- Facilite la documentation de votre code
Code plus facilement installable & déployable¶
- Facilite l'installation en local ou depuis un serveur :
pip install my-package - Facilite grandement le déploiement continu (CD) de votre code sur un serveur distant ou un dépot (par exemple avec Heroku)
- Essentiel à l'intégration continue (CI) en permettant de faire des tests automatisés
Bonnes pratiques¶
Vous avez intérêt à packager votre projet pendant son développement afin de pouvoir factoriser votre code et l'appeler dans vos différents scripts et/ou notebooks. Cela vous facilitera grandement la collaboration
sound/ # racine du package
__init__.py
setup.py # script d'installation des dépendances
requirements.txt # indique les dépendances pour votre paquet
scripts/
sound-run # script shell
formats/ # sous package pour les conversions de formats
__init__.py
wavread.py # module
wavwrite.py
...
effects/ # sous package pour les effets de sons
__init__.py
echo.py
surround.py
reverse.py
...
[OPTIONNEL] inclure un le fichier Makefile¶
L'utilisation la plus fréquente de Makefile est celle permettant de décider quelle partie du code d'un large programme à besoin d'être compilé (très souvent utilisé en C/C++). Plus généralement, il peut servir comme un gestionnaire de lignes de commandes, suivant les caractéristiques :
targets: prerequisites
some_command
some_command
some_command
On peut alors intégrer un Makefile à notre package afin, par exemple, de faciliter la gestion des lignes de commandes pour son installation, l'éxecution de tests, ...
sound/ # racine du package
__init__.py
Makefile # gestionnaire de lignes de commandes
setup.py # script d'installation du package
requirements.txt # indique les dépendances pour votre paquet
scripts/
sound-run # script shell
formats/ # sous package pour les conversions de formats
__init__.py
wavread.py # module
wavwrite.py
...
effects/ # sous package pour les effets de sons
__init__.py
echo.py
surround.py
reverse.py
...
Example de Makefile¶
install_requirements:
pip install -r requirements.txt
install:
pip install .
install_dev:
pip install -e .
uninstall:
pip uninstall -y my-package
test:
coverage run -m pytest tests/*.py
clean:
rm -f .coverage
rm -Rf */__pycache__
rm -Rf */*.pyc
all: install_requirements install test
Usage¶
A l'endroit ou est situé le fichier 'Makefile':
make install
make test
...
make all
[OPTIONNEL] inclure un le fichier MANIFEST.in¶
Le fichier MANIFEST.in peut s'utiliser lorsque vous construisez la distribution du code source de votre package en vous permettant de gérer l'inclusion ou l'exclusion de fichiers supplémentaires aux fichiers inclus par défaut.
Vous pourriez avoir envie d'y inclure par exemple des fichiers concernant les auteurs et contributeurs, un dossier de documentation, un changelog....
sound/ # racine du package
__init__.py
setup.py # script d'installation des dépendances
requirements.txt # indique les dépendances pour votre paquet
scripts/
sound-run # script shell
MANIFEST.in
formats/ # sous package pour les conversions de formats
__init__.py
wavread.py # module
wavwrite.py
...
effects/ # sous package pour les effets de sons
__init__.py
echo.py
surround.py
reverse.py
...
Pour plus de détails, voir la documentation de la python packaging authorithy (pyPA)
Notion d'intégration et de déploiement continu (CI/CD)¶
Continous Integration (CI)¶
Processus d'intégration automatisée de changements de code produit par différents contributeurs tout au long de la phase de développement d'un logiciel.
Il s'agit d'une pratique très courante dans l'approche DevOps, elle permet de réaliser très fréquement des fusions de changements de code dans un dépot central d'un système de controle de version.
Très souvent, le système de contrôle de version choisi propose des fonctionnalités supplémentaires permettant de réaliser des vérifications avant l'intégration du code:
- outils de revue de code
- tests automatisés pour vérifié que le code est correct
- tests automatisés pour vérifier la bonne syntaxe (par ex le PEP 8)
- ...
Bonnes pratiques de CI¶
Test Driven Developement (TDD)¶
C'est une approche consistant à produire des programmes de test de code pour chaque fonctionnalité du logiciel en cours de développement. Ces tests permettent de vérifier que le nouveau code fonctionne comme attendu avant d'être intégré à la chaîne de traitement pour l'intégration continue.
Demande de fusion et de revue de code¶
Dans l'approche DevOps, la plupart des équipes de développement modernes intégrent des pratique de pull request et de revue de code dans leur processus d'intégration continue:
- Un développeur développe du code pour une fonctionnalité du logiciel en utilisant une branche dédiée
- Lorsqu'il à terminé le développement du code, il fait une demande de fusion de son travail (
pull requestdansgithuboumerge requestdansgitlab) pour l'intégrer au code déja en prdouction sur la branche principale - Un autre développeur (en général un mainteneur) fait une revue de son code et peux demander des changements dans le code pour qu'il soit conforme à ce qui est attendu (fonctionnalité, calité du code, ...)
- Lorsque le mainteneur juge le code conforme, il le fusionne au code en cours sur la branche dédiée à la production
Optimisation de la vitesse de la chaine de traitement (pipeline)¶
Etant donné l'utilisation fréquente de la pipeline d'intégration continue, il est important de prévoir et garantir sa vitesse d'éxécution tout au long de son cycle.
En effet, même un délai minime dans son temps d'écustion peut croître de manière importante au fur et a messure qu'augmente le nombre de branche de développement, de la taille de l'équipe de développement, du volume de code produit, ...
Pour plus de détails voir cet article d'Atlassian sur l'intégration continue
Continuous Deployement and Delievery (CD or CDD)¶
Le déploiement continu est un processus de mise en production automatisée de briques de codes d'un logiciel. Ce processus utilise des tests pour valider si des changements de code sont correct et stable (intégration continue) afin d'être intégrés et mis en production automatiquement dans un environnement dédié.
Ce processus de déploiement continu est parfois précédé d'une étape de livraison continue, qui propose une étape de validation manuelle des changements effectués avant l'entrée dans l'étape de déploiement
Illustration du concept de CI/CD avec Gitlab¶
Bonnes pratiques de déploiement continu¶
Garantir une unique méthode de développement¶
Une fois mise en place une pipeline de déploiement, il est important qu'elle devienne la seule méthode de deploiement utilisée (par exemple, aucun développeur ne doit plus copier du code manuellement en dehors de la pipeline)
Pour plus de détails voir cet article d'Atlassian sur le déploiement continu
Virtualisation & Conteneurisation¶
La virtualisation est un paradigme permettant de créer à l'intérieur d'unn système d'exploitation, de mutliples instances de logiciels isolés. Du point de vue du système d'exploitation, ces instances de logiciels se comportent comme de vrais logiciels.
Par exemple, une machine virtuelle est un composant logiciel émulé permettant de lancer un système d'exploitation à l'intérieur du système d'exploitation hôte.
Les conteneurs sont un autre exemple de composant logiciel virtuel, qui permettent de packager différents composants logiciels comme des couches. De fait, les conteneurs ne contiennent pas nécessairement de couche logicielle de système d'exploitation, ce qui rend généralement leur usage plus flexible et moins couteux en ressources computationnelles que les machines viruelles.
Docker¶
Docker est des logiciels les plus utilisés pour créer et gérer des conteneurs. Son principal avantage réside dans le fait qu'il permet de packager une application et toutes ses dépendances dans un unité logcielle standardisée et isolée.
Pour plus de détails sur se familiariser avec l'utilisation de docker, vous pouvez voir ce tutoriel
Exemple de pipeline CI/CD avec github¶
Nous allons ajouter à notre package un sous package de test destinés à contenir les tests automatisés:
sound/ # racine du package
__init__.py
Makefile # gestionnaire de lignes de commandes
setup.py # script d'installation des dépendances
requirements.txt # indique les dépendances pour votre paquet
scripts/
sound-run # script shell
formats/ # sous package pour les conversions de formats
__init__.py
wavread.py # module
wavwrite.py
...
effects/ # sous package pour les effets de sons
__init__.py
echo.py
surround.py
reverse.py
...
tests/ # sous package pour les tests automatisés
__init__.py
test_waveread.py
test_wavewrite.py
test_echo.py
...
Exemple de test basique¶
pour notre module wavread, on pourrait mettre en place plusieurs tests, en fonction de ce que ce module est censé faire. Par exemple, vérifier que la piste son en entrée soit bien au format .wav:
def test_is_wav_suffix(file):
# test file extenstion
assert file.split('.')[-1] == "wav"
et faire éxécuter ce test, en utlisant par exemple le module pytest :
pytest tests/test_is_wav_suffix.py
Intégration de tests dans une pipeline¶
Pour mettre en place ce type de pipeline, il vous suffira d'intégrer à votre package un fichier de configuration décrivant les tests à réaliser:
Pour gitlab¶
sound/ # racine du package
__init__.py
Makefile # gestionnaire de lignes de commandes
setup.py # script d'installation des dépendances
requirements.txt # indique les dépendances pour votre paquet
scripts/
sound-run # script shell
formats/ # sous package pour les conversions de formats
...
effects/ # sous package pour les effets de sons
...
tests/ # sous package pour les tests automatisés
__init__.py
test_waveread.py
test_wavewrite.py
test_echo.py
...
.gitlab/
gitlab-ci.yml/
Pour github¶
sound/ # racine du package
__init__.py
Makefile # gestionnaire de lignes de commandes
setup.py # script d'installation des dépendances
requirements.txt # indique les dépendances pour votre paquet
scripts/
sound-run # script shell
formats/ # sous package pour les conversions de formats
...
effects/ # sous package pour les effets de sons
...
tests/ # sous package pour les tests automatisés
__init__.py
test_waveread.py
test_wavewrite.py
test_echo.py
...
.github/
workflows/
pythonpackage.yml
Quelques stratégies pour la mise en place de serveurs¶
Mettre en place vos propres serveurs¶
En fonction de vos besoins, vous pouvez mettre en place différents types de serveurs:
- une serveur de base de données
- uns serveur d'application / un serveur web
- un serveur de calcul
- ...
Avantages¶
- vous controlez en totalité vos données
- vous choisissez les technos utilisées
- vous maitrisez vos couts de manière plus transparente
Inconvénients¶
- de nombreuses compétences nécessaires en fonction des technos utilisées
- la maintenance
- l'optimisation (vitesse, temps d'accès)
- les risques liés a la cyber sécurité
Utilisation des services dans le cloud¶
L'importance prise par le cloud ces dernières années, rend l'utilisation de services pour la data science (serveurs de stockage, serveurs de calcul pour l'IA, deploiement de conteneurs) de plus en plus facile d'usage et automatisable
Les géants de la tech proposent une multitude de services pour la data science & l'IA via leurs plateformes:
Avantages¶
- des outils puissants et assez simples à prendre en main
- des services avec un haut niveau d'automatisation et de scalabilité
- peu d'investissement de départ
- maintenance et mise à jour assuré par le fournisseur de services
Inconvénients¶
- faible contrôle sur les données
- le prix des services pay-as-you-go qui peut revenir cher en cas d'utilisation récurrente
- le risque de dépendance à un fournissuer de services
Stockage dans le cloud¶
La quasi totalité des acteurs proposent des solutions de stockage en ligne allant d'espace disque (souvent nommés buckets) aux entrepots (data warehouse) ou lacs de données (data lake), en passant des bases de données de différents types, SQL, NoSQL, ..
Dans le cadre de cours, vous pourrez la plupart du temps vous pouvez vous contenter d'utiliser des buckets pour stocker les données dont vous aurez besoin, par exemple, pour un fonctionnement basique:
- un dossier pour stocker les data set
- un dossier pour stocker les modèles (
.pickle,.joblib) - un dossier pour stocker le code packagé de votre application
⚠️ Attention à configurer minutieusement les permissions d'accès et en vous identifiant avec ces accès, vous pourrez alors accéder à ces buckets via une adresse distante, fournie par le service.
Construire une interface graphique¶
De plus en plus d'outils ... en python¶
Si traditionnellement il n'exitait peu d'autres moyens que de créer son interface graphique qu'en la programmant dans un lanage dédié, souvent le HTML, il existe maintenant de plus en plus de logiciels pour créer une interface graphique en python pour vos projets en data science
plus ou moins adaptée en fonction de vos besoins pour concevoir une application orientée data science.
Il convient de choisir le logiciel correspondant le mieux à vos besoins !
| Notebook | Dashboarding | Orienté Data Science | Micro framework | Framework web | Librairies graphiques | |
|---|---|---|---|---|---|---|
| Exemple | Jupyter | Bokeh/Panel | Dash/Streamlit | Flask | django | PyQT/Tkinter |
| Interaction utilisateur | Faible | Faible | Moyenne | Moyenne/Elevée | Elevée | Très élevée |
| Niveau de fonctionnalités | Faible | Faible | Moyen/Elevée | Elevé | Elevé | Très élevée |
| Complexité | Très Faible | Faible | Faible | Moyenne/Elevée | Elevée | Très élevée |
Focus sur streamlit¶
Streamlit est un framework populaire en python spécialisé dans les interfaces graphiques pour la data science. Il possède des fonctionnalités avancées pour la création et le déploiement d'applications.
Fonctionnement¶
Streamlit interprète du code python pouvant contenir des variables (numériques, string, du markdown,...) des objets (array, dataframes, ...), des graphiques ou encore des actions (boutons, sélecteur, boite de dialogue, ...)
Le code est interpété de haut en bas et streamlit affiche dans le navigateur chaque élément rencontré
Exemple de code d'une petite application¶
import numpy as np
import pandas as pd
import streamlit as st
st.markdown("""# This is a header
## This is a sub header
This is text""")
df = pd.DataFrame({
'first column': list(range(1, 11)),
'second column': np.arange(10, 101, 10)
})
# this slider allows the user to select a number of lines
# to display in the dataframe
# the selected value is returned by st.slider
line_count = st.slider('Select a line count', 1, 10, 3)
# and used in order to select the displayed lines
head_df = df.head(line_count)
head_df
lancer une application¶
streamlit run app.py
Déployer une application (démo)¶
Le moyen le plus simple pour déployer une application streamlit est d'utiliser sur cloud à partir d'un fichier python ou d'un dépot GitHub
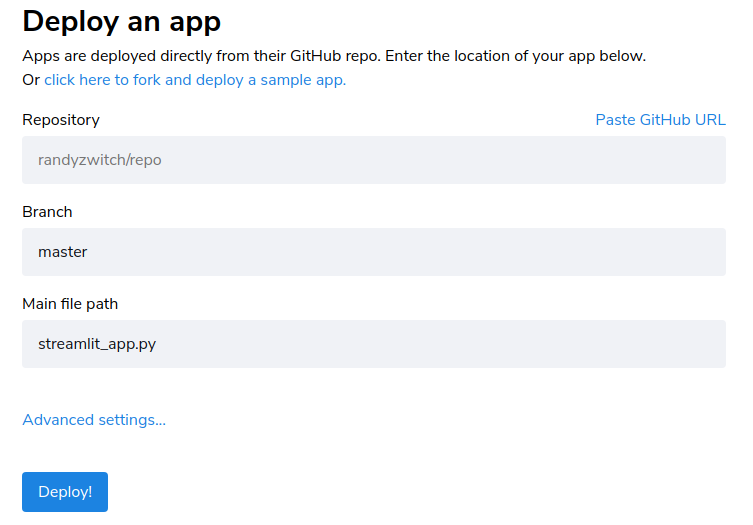
Vous pouvez aussi déployer votre application sur votre propre cloud, en utilisant des containers dockers
Quelques exemples d'applications réalisées par la communauté¶
La section Gallerie expose quelques applications crées par les utilisateurs. Explorons en quelques une ensemble, pour appréhender une partie des capacités de streamlit:
Pour aller plus loin avec Streamlit¶
Jettez un oeil à la documentation ou au groupe de discussion.
Vous trouverez également beaucoup de tutoriels en ligne, par exemple sur le blog Towards data science
Construire une API¶
Définition d'une API¶
Une Application Programming Interface (API) sert d'intermédiaire pour connecter plusieurs ordinateurs ou plusieurs programmes, servant à faire "dialoguer" ces ordinateurs/programmes entre eux.
Il s'agit d'un ensemble normalisé de programmes (classes, fonctions, constantes, ...) généralement partagée sous forme de bibliothèque ou de service web. Elle accompagné par une description qui spécifie comment les programmes consommateurs peuvent se servir des fonctionnalités du programme fournisseur
De nos jours, les APIs sont employées dans de nombreux logiciels, souvent pour faire des requêtes pour récupére, écrire ou suprrimer des données. Elle sont fournies avec des spécifications fournies sous forme de documentation par le fournisseur du logiciel.
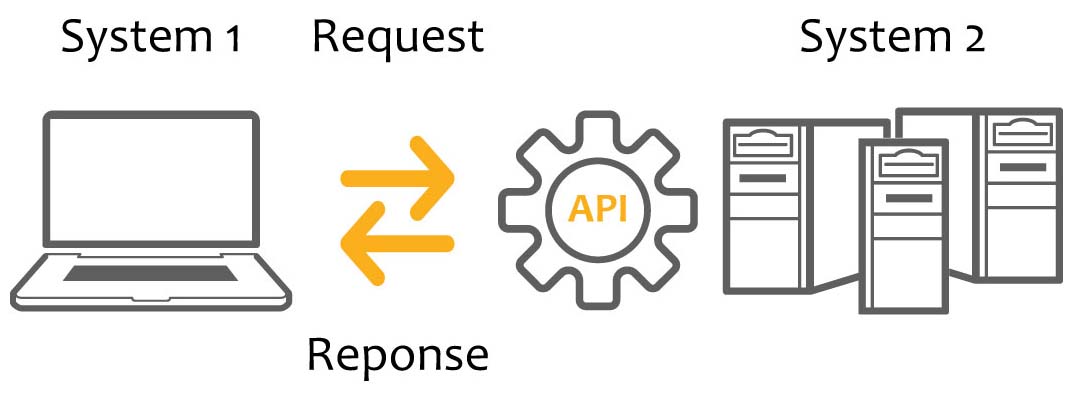
Exemple d'API¶
Par exemple, un moteur de recherche fonctionne en utilisant une API lui permettant une requête HTTP à un serveur web qui répond en lui renvoyant du code HTML qui permet au navigateur web d'afficher le résultat du classement des url des pages web recherchées.
Intérêt d'une API en pour dialoguer avec une interface graphique¶
En data science, l'API sera souvent utilisée pour faire des requêtes pour afficher dans une interface graphique utilisateur (GUI) des résultats provenant de vos analyses, par exemple, les prédictions d'un modèle en fonction des données entrées par l'utilisateurs

Exemple avec Fast API¶
Installation¶
pip install fastAPI
Création de l'API¶
FastAPI utilise des décorateurs python pour configurer chacune des routes et leur endpoints (point d'arrivée sur le serveur) pour créer toutes les requêtes dont l'interface (GUI) aura besoin pour dialoguer avec le serveur.
Le code des fonctions décorée sera appelé uniquement au moment ou une requête HTTP est reçue par le serveur web qui renverra un fichier JSON contenant les informations demandées
from fastapi import FastAPI
api = FastAPI()
# defini le endpoint root "/"
@api.get("/")
def index():
return {"ok": True}
# défini le endpoint "/predict"
@api.get("/predict")
def predict(day_of_week=None, time=None):
# calcule une variable `wait_prediction` à partir `day_of_week` and `time`
if (day_of_week==None) or (time==None):
return {"wait": "missing value"}
else:
return {'wait': wait_prediction}
Afin de faire fonctionner cette API, il nous faut installer un serveur web que l'on pourra déployer en local et sur un serveur distant
Créer un serveur web avec uvicorn¶
Parmi la foule d'outils possible pour créer un serveur web, nous allons utiliser Uvicorn un serveur web léger et rapide en python
Uvicorn sera chargé d'écouter les requêtes HTTP reçue par le serveur web et d'appeler le code décoré dans fastAPI correspondant au endpoint de la requête
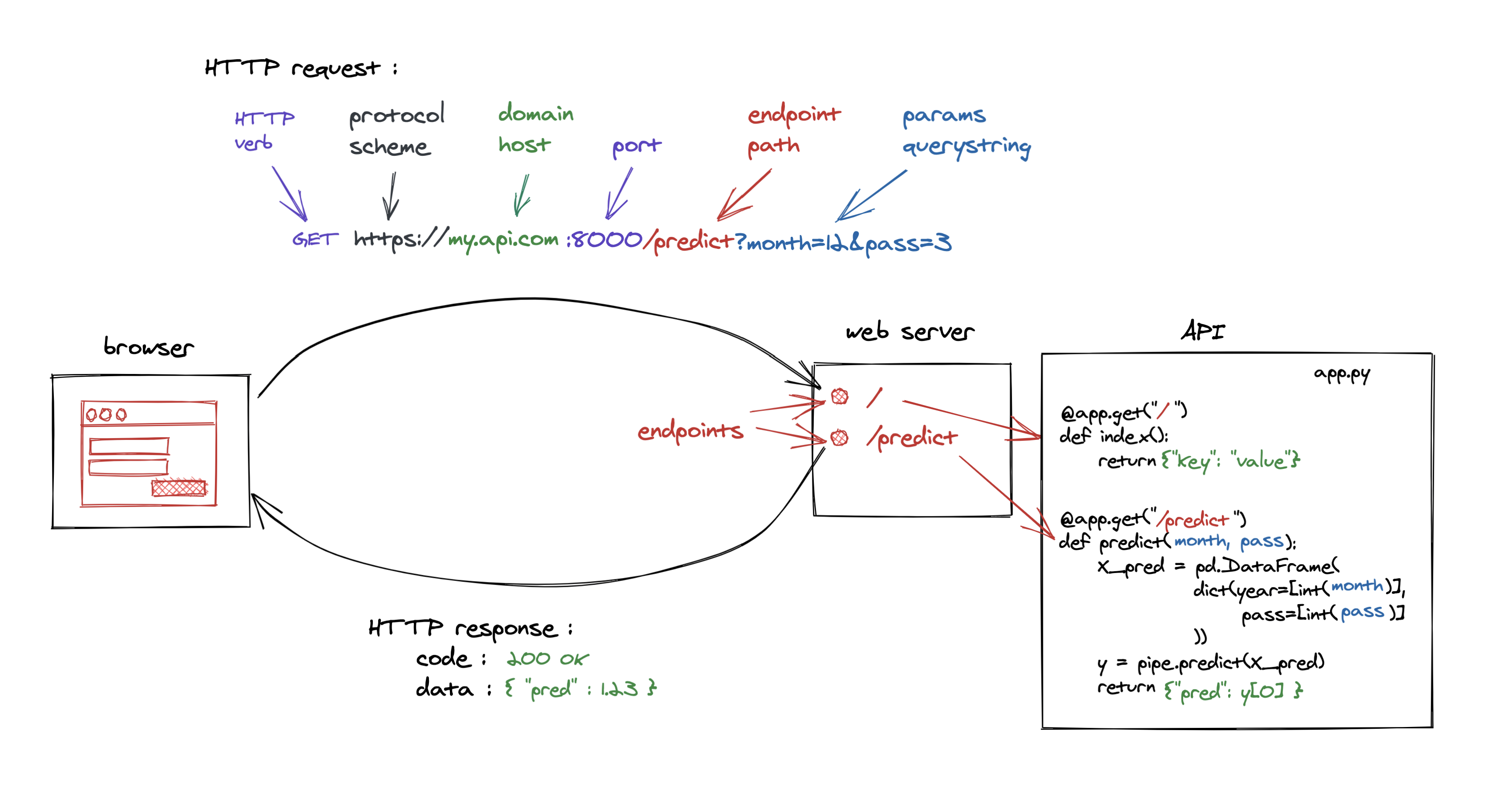
Installation¶
pip install uvicorn
Usage¶
uvicorn <nom_fichier_api>:<instance de FastAPI> --reload
uvicorn simple_api:api --reload
l'API est accessible à l'adresse http://localhost:8000/
FastAPI a généré automatiquement des endpoints pour deux types de documentation:
- une doc Swagger http://localhost:8000/docs
- une doc redoc http://localhost:8000/redoc
Quelques stratégies pour déployer son application¶
La plus simple : déployer son application streamlit sur leur cloud¶
Cette stratégie est particulièrement adaptée lorsque vous souhaitez déployer gratuitmement une application concue avec streamlit, par exemple un tableau de bord ou un data storytelling
⚠️ Attention le déploiement est limité a une application privée (sans limite pour des applications publiques) avec 1GB par application
Déploiement sous heroku¶
Heroku est une plateforme de déploiement automatisé et scalable (sous forme de conteneur appelé dyno), depuis un dépot Git, supportant de nombreux langages (dont python).
Elle permet un déploiement très facile automatisé, à faible cout, d'une application, ce qui la rend idéale pour le protoypage ou la mise en production de petite applications.
Exemple de déploiement¶
Nous allons faire une démo d'un simple déploiement de notre application app.py.
Celle ci-étant très basique elle n'a pas besoin d'afficher d'informations calculées à partir d'un modèle, nous n'aurons donc pas besoin dans cet exemple de déployer l'API et le serveur web uvicorn.
Dans la pratique, il est souvent courant d'avoir besoin d'une API dans son application !
Différents méthodes de déploiement¶
Tout comme d'autres services, Heroku propose différentes méthodes de déployer une application. La plus simple à utiliser pour des applications simple est le déploiement par Github
Démo de déploiement par Github¶
Voyons comme déployer par étape notre app.py sur les serveurs de Heroku
1. Disposer d'un compte sur Heroku¶
2. Packager son application¶
2.1 Créer un dépot git & github pour son application¶
git init # crée un dépot git local
gh repo create # crée un dépot distant sur github
2.2 Créer tous les fichiers de packaging & de déploiement¶
touch README.md
touch .gitignore
touch Makefile
touch MANISFEST.in
touch requirements.txt
touch setup.py
touch Procfile
touch setup.sh
.git # git local
.gitignore # git local
README.md # github
app.py # notre app
Makefile # directives
MANISFEST.in # ajout de fichiers au package
requirements.txt # liste des dépendances
setup.py # installation du package
Procfile # Heroku
setup.sh # lien entre heroku et streamlit
Makefile¶
run_streamlit:
streamlit run app.py
MANIFEST.in¶
include requirements.txt
requirements.txt¶
streamlit
setup.py¶
from setuptools import setup, find_packages
with open("requirements.txt") as f:
content = f.readlines()
requirements = [x.strip() for x in content]
setup(name="demo-streamlit-app",
version="1.0",
description="a demo of a simple streamlit app",
packages=find_packages(),
include_package_data=True, # permet d'inclure les packages trouvé dans le MANIFEST.in
install_requires=requirements)
Procfile¶
web: sh setup.sh && streamlit run app.py
Pour plus de détails concernant la création du Procfile, voir la page de Heroku dédiée
setup.sh¶
Il s'agit d'un script qui sera exécuté au moment du déploiement et permet d'automatiser certaines actions, comme par exemple, enregistrer des crédentials ou configurer un port:
mkdir -p ~/.streamlit/
# configure sur le serveur les credentials
echo "\
[general]\n\
email = \"${HEROKU_EMAIL_ADDRESS}\"\n\
" > ~/.streamlit/credentials.toml
# configure sur le serveur le port à utiliser
echo "\
[server]\n\
headless = true\n\
enableCORS = false\n\
port = $PORT\n\
" > ~/.streamlit/config.toml
2.3 Faire un commit de ces fichiers sur mon dépot local¶
2.4 Déployer l'application à partir du dépot git de Heroku¶
# cree une application sur un serveur europeen de heroku
heroku create APP_NAME --ssh-git --region eu
# pour verifier que le lien origin a ete crée vers le dépot git de Heroku
git remote -v
# si ce n'est pas le cas, ajouter ce lien manuellement
git remote add heroku https://git.heroku.com/APP_NAME.git
# deployer l'app
git push heroku master
# si nécessaire, démarre le dyno manuellement
heroku ps:scale web=1
# check the logs for errors
heroku logs --tail
Pour plus de détails concernant le déploiement par github, vous pouvez consulter la doc dédiée de Heroku
Déploiement en utilisant des conteneurs¶
Nous l'avons vu plus tôt, l'utilisation de conteneurs pour le déploiement continu est une bonne pratique, en particulier lorsque l'on souhaite controler finement les différentes couches logicielles de notre application (par exemple un serveur web ou une API)
Logique de déploiement¶
On crée un conteneur (par exemple un conteneur docker qui contiendra toutes les couches logicielles minimales nécessaires au fonctionnement de notre application. C'est ce conteneuer qui sera automatiquement executé pour assurer le déploiement.
On peut résumer (dans la plupart des services) le processus de déploiement continu en 3 étapes:
- créer en local le conteneur
- déployer le conteneur sur un
container registry(registre de conteneur) - lancer automatiquement le conteneur via un
service runtimeet ainsi mettre en production l'application
Fournisseur de services¶
Comme la plupart des services cloud, Heroku propose également de déployer des conteneurs docker.
C'est aussi le cas, par exemple, des plateformes des géants de la tech qui qui possèdent des services dédiés :
Choisir son service de déploiement¶
La plupart des plateformes de déploiement proposent des fonctionnalités équivalentes (notemment le déploiement de conteneurs docker) mais il faut tenir compte de certaines leur spécificités pour bien faire votre choix:
- la possibilité de rendre votre application scalable:
si votre application est ammenée à varier en taille, ou interagir avec de nombreux composants, ... vous aurez intérêt à utiliser un service utilisant un orchestrateur de conteneurs comme kubernetes
- le prix
- la courbe d'apprentissage du service
- l'intégration de services dont vous avez besoin ?
- ...
Pour aller plus loin¶
La démo de déploiement que nous avons faite est simpliste, vous serez souvent confronté à des cas plus complexe, comme par exemple déployer une interface graphique reliée par une API aux résultats d'un mod-le de machine learning.
Vous trouverez assez facilement des tutoriels pour ces cas d'usages, en fonction du fournisseur choisi, comme celui-ci expliquant comment déployer un modèle de machine learning sur AWS
Itérations : cycles de CI/CD¶
En pratique¶
Une fois votre application déployée, vous allez entrer dans un cycle d'itérations d'intégration et de déploiement continu afin d'intégrer progressivement les changements fréquents que vous ferez dans votre application
Par exemple pour une application utilisant des algorithmes machine learning, l'amélioration de vos modèles d'apprentissage peut consituer une source de changements importants:
- enrichissement de données: agréger des données plus récentes ou nouvelles aux données existantes
- calcul en ligne: entaîner itérativement votre modèles avec des nouvelles données
- prédiction en ligne: utiliser un modèle packagé pour faire de nouvelles prédictions
- mettre à jour les endpoints de l'API pour la connexion avec l'interface graphique
- tracker les iterations par exemple avec des outils comme mlflow
- ...