

Introduction
Chaque paquet de signal d'entrée Ethernet RIO transite d'une station RIO vers la CPU, et la CPU renvoie un signal de sortie à la station RIO. Le temps nécessaire pour que la CPU reçoive le signal d'entrée et effectue un changement dans le module de sortie d'après cette entrée est appelé temps de réponse de l'application (ART). Dans un système M580, l'ART est déterministe, ce qui signifie que vous pouvez calculer le temps maximum que la CPU utilise pour résoudre une scrutation logique RIO.
Présentation : Paramètres de calcul de l'ART
Le schéma ci-dessous indique les événements et les paramètres de calcul liés à l'ART. Pour plus d'informations, reportez-vous à l'annexe Principes de conception de réseaux M580.
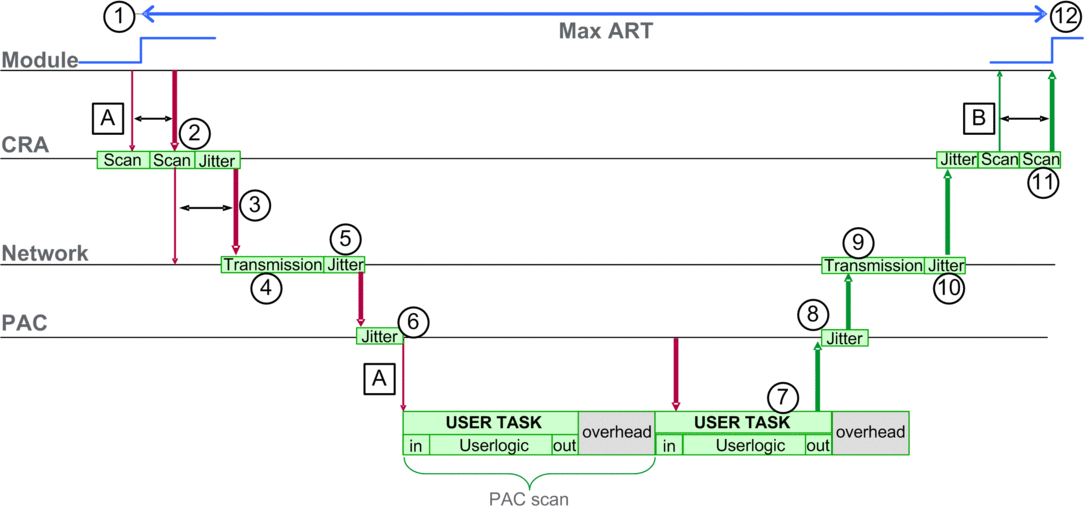
Légende :
A |
scrutation des entrées manquées |
6 |
instabilité des entrées de la CPU |
B |
scrutation des sorties manquées |
7 |
exécution de la logique de l'application (1 scrutation) |
1 |
entrée activée |
8 |
instabilité des sorties de la CPU |
2 |
temps de traitement des stations CRA |
9 |
retard du réseau |
3 |
intervalle de trame demandé (RPI) des entrées du CRA |
10 |
instabilité du réseau |
4 |
retard du réseau |
11 |
temps de traitement des stations CRA |
5 |
instabilité du réseau |
12 |
sortie appliquée |
Estimation rapide de l'ART
Pour estimer l'ART maximum en fonction du nombre maximum de modules RIO et d'équipements distribués pour une application, additionnez les valeurs suivantes :
CRA->Scrutateur RPI
2 * CPU_Scan (pour la tâche)
8,8 ms : valeur constante représentant le temps de traitement CRA maximal
Remarques concernant l'ART :
Structure multitâche |
Le calcul ci-dessus est valable pour chaque tâche. Cependant, dans une structure multitâche, les tâches de priorité plus élevée peuvent augmenter le temps de scrutation de la CPU (CPU_Scan). Lorsque les tâches MAST et FAST sont combinées (structure multitâche), la scrutation de la CPU (CPU_Scan) peut demander beaucoup plus de temps pour la tâche MAST. La structure multitâche risque d'augmenter sensiblement l'ART de la tâche MAST. |
Redondance d’UC |
Reportez-vous à la section Modicon M580 - Redondance d'UC - Guide de planification du système pour architectures courantes pour calculer l'ART pour les CPU à redondance d'UC (Hot Standby). |
câble rompu |
si un câble est rompu ou reconnecté sur le réseau, ajoutez un temps supplémentaire au calcul d'ART ci-dessus pour permettre la restauration RSTP. Ce temps supplémentaire est égal à 50 ms + RPI CRA->Scrutateur. |
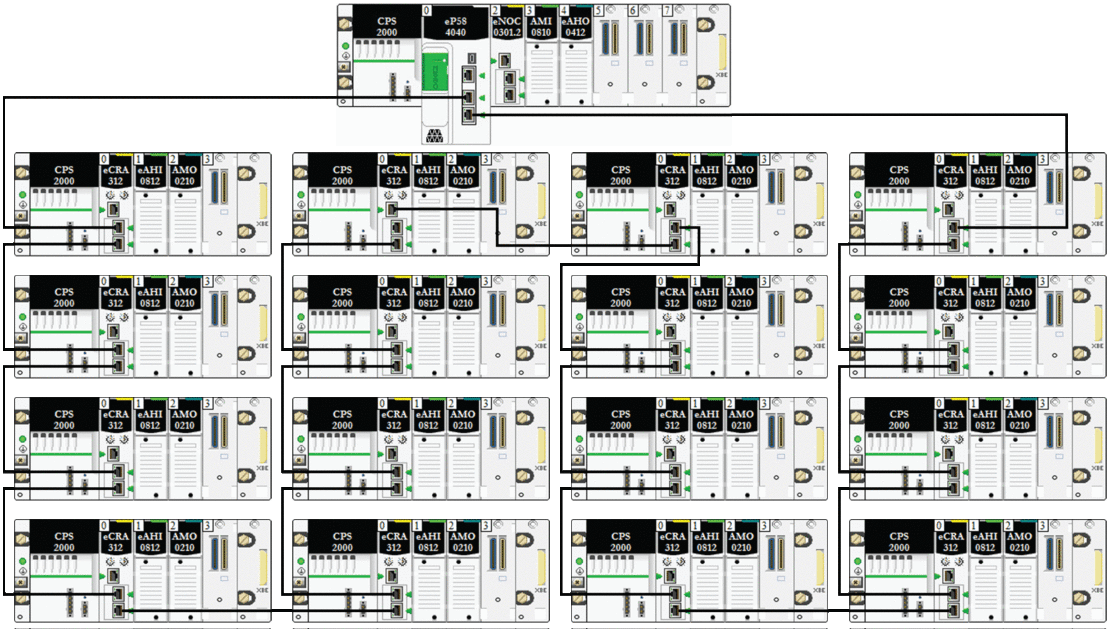
Calcul simplifié de l'ART pour une boucle de chaînage simple de modules adaptateurs BM•CRA312•0 dans un anneau principal
Dans cet exemple, l'ART est calculé du point de vue des 16 modules adaptateur X80 EIO BM•CRA312•0 connectés à la CPU du rack local via l'anneau principal :
Souvenez-vous que la formule utilisée pour estimer l'ART maximum est la suivante :
ART = RPI CRA->Scrutateur + CPU_Scan/2 + (2*CPU_Scan) + 8,8
Par conséquent, pour une tâche avec un temps de scrutation de 40 ms et un RPI CRA->Scrutateur de 25 ms, l'ART maximal est calculé comme suit :
ART max. = 25 + (2*40) + 8,8 = 113,8 ms